较低的延迟通常是以牺牲能源效率为代价的,但在新发布的实验结果中,受大脑启发的IBM NorthPole 研究原型芯片实现了比下一个最快的 GPU 低得多的延迟,并且能源效率比下一个最高效的 GPU 高得多。

随着研究人员竞相开发下一代计算机芯片,人工智能成为他们关注的焦点。随着最近生成式人工智能(包括大型语言模型)应用的激增,很明显,传统的 CPU 和 GPU 难以提供速度和能效的必要组合。为了大规模提供人工智能(尤其是对于代理工作流和数字工作者而言),运行这些模型的硬件需要运行得更快。与此同时,人工智能功耗对环境的影响是一个紧迫的问题,因此降低人工智能的功耗至关重要。在加利福尼亚州阿尔马登的 IBM Research 实验室中,一个团队一直在重新思考芯片架构的基础,以实现这两个目标,他们的最新成果展示了未来的处理器如何消耗更少的能源并更快地运行。
AIU NorthPole 是 IBM Research 去年首次推出的一款 AI 推理加速器芯片。在基于 IBM Granite-8B-Code-Base 模型开发的 30 亿参数 LLM 上运行的推理测试中, NorthPole 实现了每token 1 毫秒以下的延迟,比下一个最低延迟 GPU 快 46.9 倍。在运行 16 个通过 PCIe 通信的 NorthPole 处理器的现成薄型 2U 服务器中,该芯片背后的团队发现它可以在同一型号上实现每秒 28,356 个token的吞吐量。它在达到这些速度水平的同时,仍实现了比下一个最节能的 GPU 高 72.7 倍的能效。
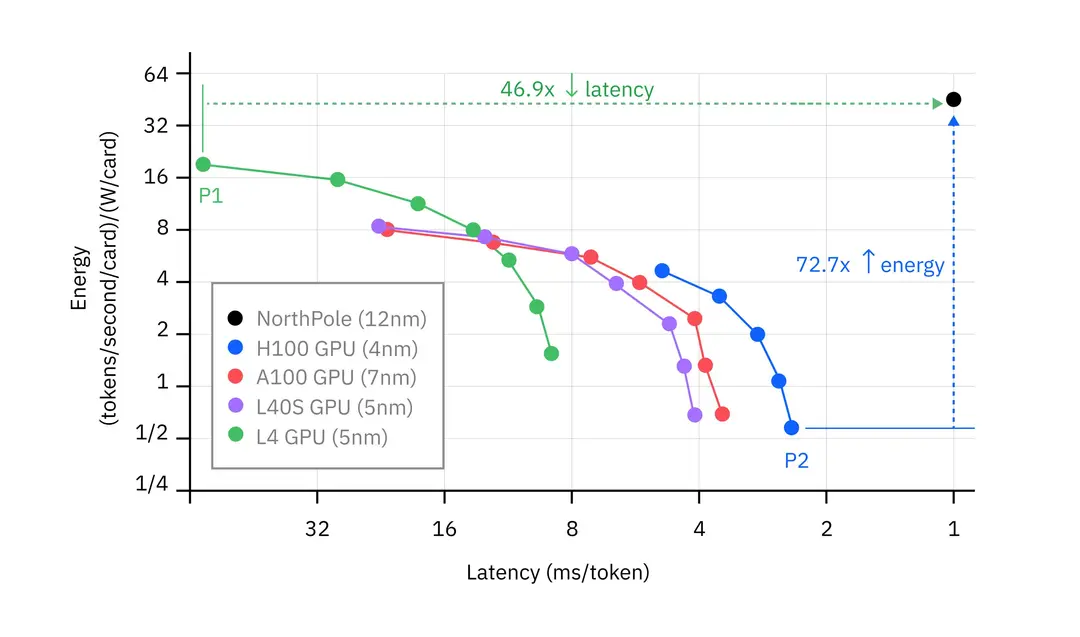
研究原型 NorthPole 比通常用于 LLM 推理的四个 GPU 具有更低的延迟和更高的能效。
该团队今天在 IEEE 高性能计算会议上展示了他们的研究成果。新的性能数据基于去年 10 月的成果,当时该团队展示了 NorthPole 能够比市场上其他边缘应用芯片更快、更高效地进行神经推理。在这些实验中,NorthPole 的能效是常见的 12 nm GPU 和 14 nm CPU 的 25 倍,以每单位功率解释的帧数来衡量。
NorthPole 采用 12nm 工艺制造,每块芯片在 795 平方毫米内包含 220 亿个晶体管。在《科学》杂志上发表的结果显示,该芯片的延迟也低于所有其他测试过的芯片,甚至比那些制造工艺更小的芯片都要低。这些测试是在 ResNet-50 图像识别和 YOLOv4 物体检测模型上运行的,因为该团队专注于自动驾驶汽车等应用的视觉识别任务。一年后,新结果来自在更大的 30 亿参数 Granite LLM 上试用 NorthPole 芯片。
“这里最重要的是质量的大幅提升。这些新成果与我们的科学成果相当,但应用领域完全不同,”领导芯片开发团队的 IBM 研究员 Dharmendra Modha 表示。“鉴于 NorthPole 的架构在完全不同的领域运行良好,这些新成果不仅强调了架构的广泛适用性,还强调了基础研究的重要性。”

标准 2U 服务器在其四个托架中每个托架可容纳四张 NorthPole 卡
Modha 表示,当企业部署代理工作流、数字员工和交互式对话时,低延迟对于 AI 的顺利运行至关重要。但延迟和能源效率之间存在根本性的矛盾——通常,一个领域的改进是以牺牲另一个领域为代价的。
降低 AI 推理延迟和功耗的主要障碍之一是所谓的冯·诺依曼瓶颈。几乎所有现代微处理器都采用冯·诺依曼架构,其中内存与处理器(包括 CPU 和 GPU)在物理上是分开的。尽管这种设计在历史上具有简单灵活的优势,但在内存和计算之间来回传送数据限制了处理器的速度。对于 AI 模型来说尤其如此,因为其计算简单但数量众多。尽管处理器效率每两年提高两倍,但内存和计算之间的带宽仅以该速度的一半左右增长。此外,高带宽内存价格昂贵。
NorthPole 的设计通过将内存和处理放在同一位置来消除这种不匹配,这种架构称为片上内存或内存计算。受大脑的启发,NorthPole 将内存与芯片的计算单元和控制逻辑紧密结合,将内存与芯片的计算单元和控制逻辑紧密结合。这带来了每秒 13 TB 的庞大片上内存带宽。
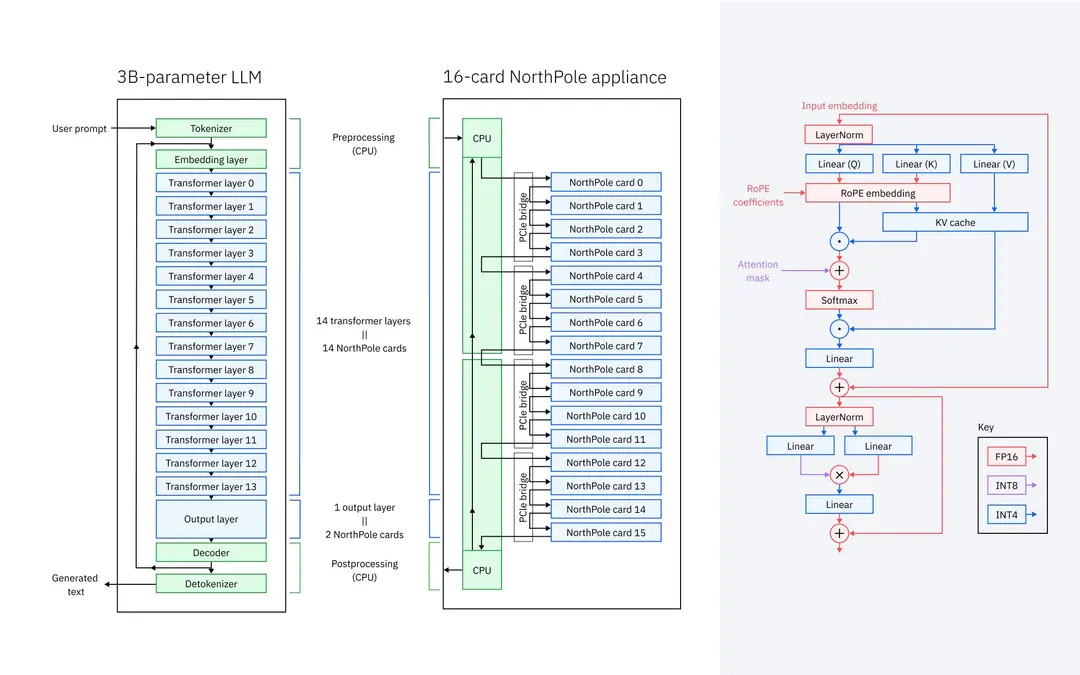
NorthPole 团队将 30 亿参数的 LLM 映射到 16 张卡片上:每张卡片上有 14 个变换器层,两张卡片上有 1 个输出层
该团队的下一个挑战是看看专为边缘推理而设计的 NorthPole 是否适用于数据中心的语言模型。一开始,这似乎是一项艰巨的任务,因为 LLM 不适合 NorthPole 的片上内存。
为了应对挑战,该团队选择在 16 卡 NorthPole 设置上运行 30 亿参数的 Granite LLM。他们将 14 个变压器层映射到每张卡上,并将输出层映射到其余两张卡上。LLM 通常受内存带宽限制,但在这种流水线并行设置中,只需在卡之间移动很少的数据 - PCIe 就足够了,并且不需要高速网络。这是存储模型权重的片上内存和所谓的键值 (KV) 缓存的结果,这意味着在生成token时需要在单独的 PCIe 卡之间传递更少的数据。该模型被量化为 4 位权重和激活,并且量化模型经过微调以匹配准确性。
根据最新实验的成功,Modha表示,他的团队目前正致力于构建包含更多北极芯片的单元,并计划在这些单元上映射更大的模型。
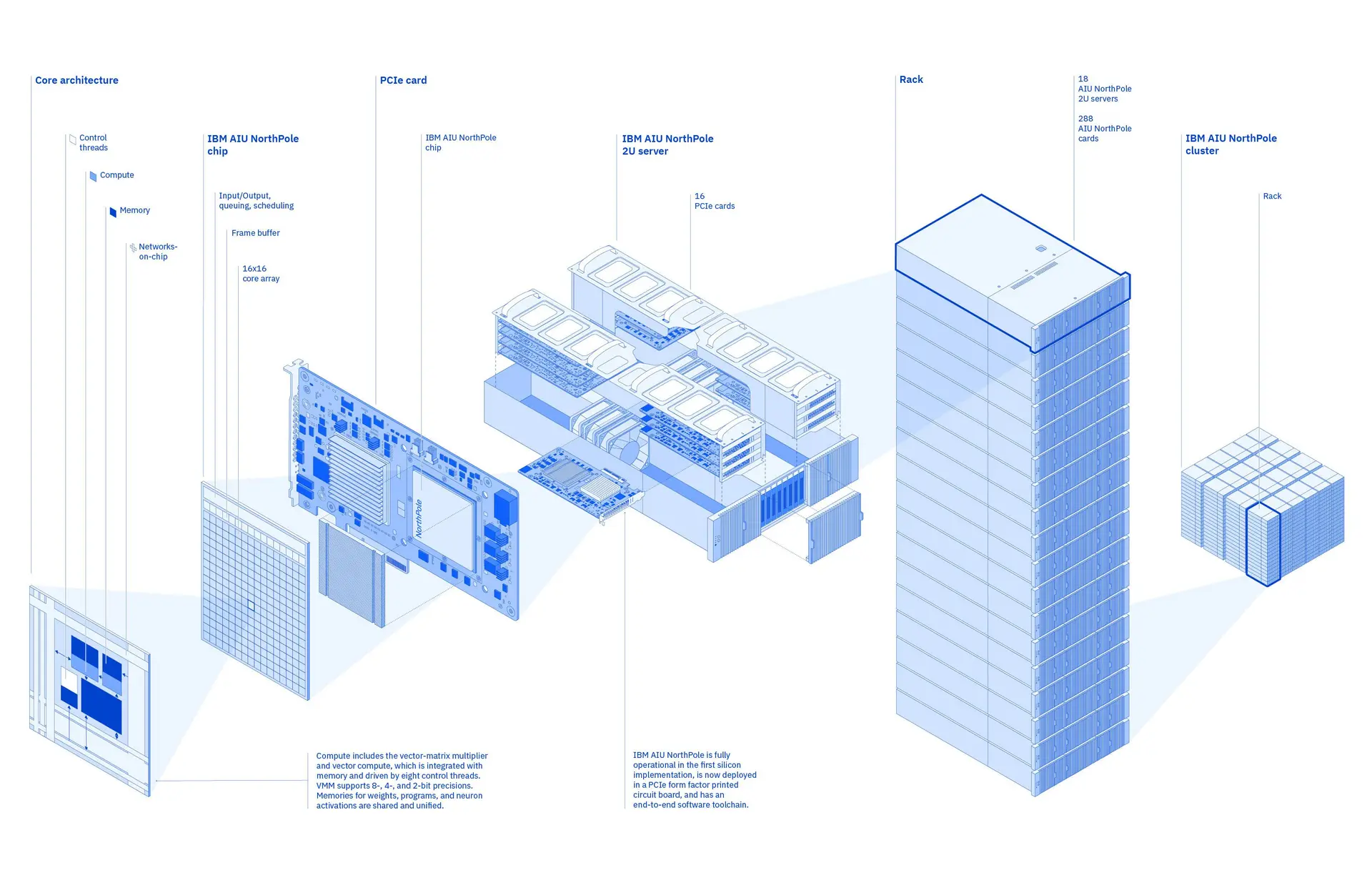
IBM 研究科学家正在致力于开发装有数百张 NorthPole 卡的服务器机架,以便以比同类基于 GPU 的硬件更快的速度和更低的能耗执行大量推理操作。
尽管新的性能结果具有开创性,但 Modha 相信他的团队将继续将前沿技术推向更高水平,以提高 NorthPole 的能源效率,同时降低其延迟。他说,关键是在整个垂直堆栈中进行创新。这将需要从头开始共同设计在下一代硬件上运行的算法,利用技术扩展和封装,并设想全新的系统和推理设备——他和 IBM 研究部门的其他人目前正在研究这些进步。
