1. VxWorks7内存管理模型
VxWorks7为执行在内核态与用户态的所有代码都提供了内存管理机制。对于32位与64位CPU,VxWorks7所提供的内存管理机制是相同的。
内核上下文不是一一映射的,也就是说虚拟内存地址与物理地址不是一一映射的。虚拟内存被分区管理,每个分区具有专门的用处和相应的分配机制。
VxWorks7内存模型用于:
- 使系统能够支持更大容量的RAM;
- 使系统能够支持RAM中不连续的块空间;
- 更快、更高效的系统调用内存验证;
- 减少了虚拟地址空间碎片;
- 可以根据需求实现内存与I/O空间的动态映射(而不是使用静态配置的代码);
- 简化使用标准ABI开发共享库的过程,该过程需要基于预定义的虚拟内存布局实现标准的重叠地址空间管理;
显示内存布局信息
shell中的adrSpaceShow()函数(针对C解释器)或adrsp info命令(针对命令解释器),可以用于显示当前地址空间使用的概况。这两者分贝包含在INCLUDE_ADR_SAPCE_SHOW与INCLUDE_ADR_SPACE_SHELL_CMD两个组件中。
虚拟内存区域
VxWorks定义了多个虚拟内存区域。这些区域是根据处理器架构进行地址和大小划分的,具有特定的作用。虚拟内存区域如下图所示。
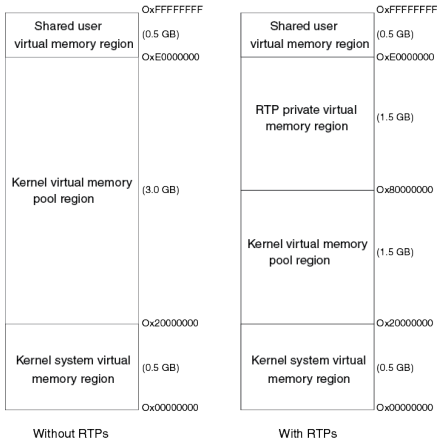
(1)内核系统虚拟内存区
内核系统虚拟内存区包含了内核系统内存。从中可以定位到内核镜像(text、data、bss)、内核临接堆(kernel proximity heap,即靠近内核内存的对空间),等等。
(2)内核虚拟内存池区
内核虚拟内存池用于在内核中实现内存的动态管理。该区域用于按需分配虚拟内存,如创建和扩展内核应用程序、内存映射设备、DMA内存、用户保留内存和一致性内存等需求。有关内核虚拟内存池更详细的信息可以通过adrSpaceShow()函数获取。
(3)内核保留内存区
该内核区域供VxWorks内部使用而保留,例如可以用于管理MMU页表结构体。
(4)共享用户虚拟内存区
共享用户虚拟内存区用于为共享映射分配虚拟内存,如共享数据区、共享库、使用mmap()的MAP_SHARED选项进行内存映射等等。更详细的信息可以adrSpaceShow()函数获取。
(5)RTP私有虚拟内存区
RTP私有虚拟内存区用于创建RTP的私有映射:代码与数据段、RTP堆空间以及使用mmap()的MAP_PRIVATE选项进行内存映射等等。在系统中的所有RTP都可以访问整个RTP私有内存区。所以,RTP使用重叠地址空间管理。
全局RAM内存池
全局RAM内存池适用于动态分配RAM空间的内部分配机制。VxWorks使用该内存池用于创建或扩充:内核通用堆(kernel common heap)、RTP私有内存与共享内存。全局RAM内存池也为如下对象提供内存:VxWorks内核镜像、用户保留内存、持久内存、DMA32堆空间,等等。
内核内存映射关系
下图展示了内核内存映射关系(不包括保留区)。
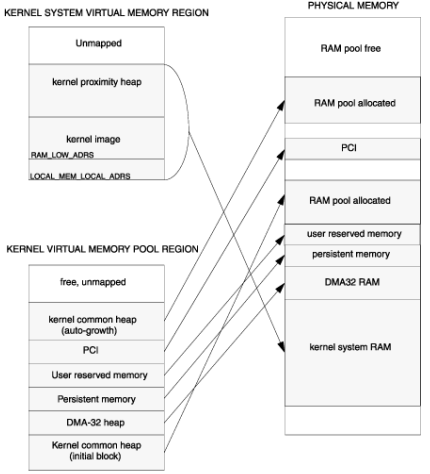
(1)内核系统内存(kernel system memory)
内核系统内存位于内核系统(虚拟)内存区,其中包括内核代码段、中断栈、用于初始化VxWorks任务的内存、内核邻接堆,还有用于存放启动参数区和异常消息区的特殊存储区域。内核系统内存在虚拟与物理空间都是一个连续的块空间。虚拟内存的起始地址由LOCAL_MEM_LOCAL_ADRS定义。其大小为其中存放内容的大小之和,其中包括了内核镜像、内核邻接堆等等。用于内核系统内存的RAM空间由BSP配置。
(2)内核通用堆(kernel common heap)
内核通用堆是供内核与内核应用程序进行动态内存分配的内存区域。物理内存是从全局RAM内存池中分配,虚拟内存是从内核虚拟内存池区分配。
(3)DMA32 Heap
DMA32堆是供设备驱动使用的内存区域。其中,这些设备不具备访问4GB以上物理地址空间的能力(如32位PCI设备)。虚拟地址是从内核虚拟内存池区中动态分配。DMA32堆的物理地址和大小由BSP提供。
(4)用户保留内存(user-reserved memory)
用户保留内存是RAM中一个可选的、由内核映射的(但不是直接由内核管理)区域。它由运行在内核中的应用程序管理。用户保留内存的虚拟空间由内核虚拟内存池区分配。可以通过userReservedMem()函数获取用户保留内存的起始地址、大小等信息。
(5)持久内存(persistent memory)
持久内存是RAM中的一个可选的、在热复位时不会被清空的区域。持久内存的虚拟空间由内核虚拟内存池分配。持久内存由pmLib API管理。持久内存主要用于如下内核服务:错误检测与报告服务、core dump服务。
内核通用堆(kernel common heap)
内核通用堆是一个供内核与内核应用程序进行动态内存分配的内存区域。该堆空间由标准的ANSI内存分配函数malloc()、free()等进行管理。
内核通用堆也用于为从主机系统下载的内核模块分配内存。默认情况下,下载的内核模块的内存空间由内核邻接堆分配。
该堆的初始值由KERNEL_COMMON_HEAP_INIT_SIZE内核配置参数指定(单位为字节)。内核通用堆支持自动增长。如果当前堆空间不能满足分配需求,操作系统将自动从内核虚拟内存池区和全局RAM内存池分配更多的内存。堆空间增长的大小应该是KERNEL_COMMON_HEAP_INCR_SIZE内核配置参数的整数倍。如果将该参数设置为0,则将关闭自动增长功能。
广义上将,对该区域中的分段没有数量限制。狭义上,堆确保了么诶一个分配的块的内存在物理上是连续的,所以如果基于全局RAM内存池中可用的连续物理内存,内核通用堆的分段是受系统限制的。段大小决定了可以从该区域分配的最大内存块。需要注意的是mmap()函数使用的内存区域在物理上是不连续的。
内核邻接堆(kernel proximity heap)
内核邻接堆是在内核系统中创建的一个内存区域,使用kProHeapLib API进行管理。
内核邻接堆也可用于(默认情况下)为从主机系统下载的内核模块分配内存。该模块必须按照内核代码模型进行编译。也可以从内核通用堆中为内核模块分配内存。
此外,内核邻接堆还可以用于为中断调用函数或其他包含可执行代码的内容分配空间。
内核邻接堆是第一个被初始化的内存分配机制。在系统启动的早期(内核通用堆创建之前),VxWorks库使用内核邻接堆进行常规的内存分配。这些过程不受代码模型需求所影响。
内核邻接堆从内核系统RAM的空闲区域创建(不再用于内核代码)。该堆的大小有KERNEL_PROXIMITY_HEAP_SIZE参数指定。
DMA32堆
DMA32堆是供设备驱动使用的内存区域,但是这些设备不具备访问大于4GB物理地址空间的能力(如32位PCI设备)。DMA32堆由cacheDMA32Lib API管理。
通常,该堆的物理内存位于RAM中的低4GB空间,由BSP配置。虚拟内存则由内核虚拟内存池区分配。
2. 物理内存映射库
VxWorks使用pmapBaseLib库实现内核与RTP上下文的物理地址映射(map)或关闭映射(unmap)。
使用该库可以允许驱动或其他模块,如图像层,使用标准的接口实现对物理内存的map和unmap。为了在VxWorks镜像中使用物理地址映射库,需要在VIP项目中添加INCLUDE_PMAP_LIB组件。更对信息参考pmapBaseLib API。
3.VxWorks内存分配
VxWorks内存分区、内存池和私有mmap()机制可用作多种用途,且各具优势。如下所示:

4. RTP堆与内存区域管理
VxWorks为RTP提供了堆与内存分区管理支持。默认情况下,堆被实现为进程的一个内存分区。
堆是在进程初始阶段自动创建的。初始化大小和自增大小由环境变量HEAP_INITAL_SIZE、HEAP_SIZE与HEAP_MAX_SIZE设定。环境变量仅在应用程序启动时有效,应用程序不能修改这些值。
内存分区是一些连续的内存区域,用于供应用程序动态地分配内存。引用程序可以创建自己的分区,并从这些分区分配和释放内存。
由进程创建的堆和任何分区都是进程私有的,也就是说只有该进程允许从这些分区分配或释放内存。
可选的堆管理器
VxWorks的进程堆实现可以由自定义的函数代替,仅需要在应用程序中链接代替的函数即可(代替的函数库在链接时必须放在vxlib.a之前)。
用作堆空间的内存可以按照如下方式获取:
一个静态创建的数组变量。该方案简单,但只能创建一个固定大小的堆;
使用动态内存映射函数mmap()。使用mmap()可以实现对空间大小的自增。然而需要重点注意的是,mmap()之后的调用不能保证能够提供连续的内存块空间。
静态创建数组变量
char heapMem[HEAP_SIZE];
如果应用程序自动链接了libc.so(其中默认包括memLib.o),那么将自动创建由memLib提供的默认堆。为了避免创建默认堆,可以创建一个自定义的不包含memlib.o的lic.so。
5. VxWorks内核堆与内存区域管理
原理同上,略。
6. 内存分配优化
供内核与RTP使用的memPartCacheLib库可以用于内核空间扩展和用户对空间管理,从而提升经常进行动态内存分配的任务的执行速度。
加速的方式是通过减少对堆管理器关键区的竞争实现的,这些竞争将由一个互斥信号量控制。该方法依赖于任务级私有数据结构,从而使任务可以再不适用锁的情况下,频繁地分配和释放内存块。从概念上讲,这就好比内存的缓冲cache。分配给每个任务的内存被分为各种块,每个块代表了一个给定的分配大小。memPartCacheLib通过malloc()与free()函数实现最大512字节的内存分配与释放。分配大于512字节的操作由内存分区函数直接执行。内存块的大小是经过划分的,小的块由16字节大,大点的有32字节,最大的空间为64字节。
该特性同时支持SMP和单核配置。通过避免多线程或多核竞争同一个内存分区锁,实现了性能提升。同时,通过更快的算法,实现了快速重用已释放的内存块空间。
内核任务配置
为了使能系统堆的任务级缓存,需要配置INCLUDE_MEM_PART_CACHE组件。
默认情况下MEM_PART_CACHE_GLOBL_ENABLE配置参数是设置为FALSE的,它为每个任务提供了任务级缓存。除非一个任务调用了memPartCacheCreate()函数,否则该功能不会使能。
如果这个参数设置为TRUE,那么将使能对所有任务的任务级缓存。当任何任务创建之后,任务级缓存将自动使能。当一个任务被删除,任何处于缓存中的内容都将释放。
RTP任务实现
为了使能进程堆的任务级缓存,RTP应用程序必须链接memPartCacheLib库,且在运行时必须使能cache。为了在应用程序中链接memPartCacheLib,需要使用链接选项-uincludeMemCache。或者,可以在应用程序中添加如下代码行:
extern BOOL includeMemCache;includeMemCache=TRUE;
之后为了给在RTP中的所有任务使能内存缓存,需要在RTP启动时将环境变量MEM_PART_CACHE_GLOBAL_ENABLE设置为TRUE。
如果环境变量MEM_PART_CACHE_GLOBL_ENABLE没有设置,还可以使用memPartCcheCreate()函数实现独立任务的内存管理优化。如果需要,可以调用memPartCacheDelete()函数关闭一个任务的缓存。当任务调用memPartCacheDelete()函数时,由该任务分配和使用的内存依旧有效,可以在之后释放。只有未被使用的且已经缓存的内存块会被自动返回到堆分区。
7. 内存池
内存池是由一系列具有静态大小的内存空间组成的一个动态集合。通过最小化从内存分区分配的大小,内存池提供了一个快速、高效的内存管理机制。应用程序通过内存池获取大量的、确切大小的内存空间。使用内存池也可以减少因频繁分配释放内存导致的内存碎片。
系统可以使用内存池进行频繁的、固定大小的内存分配与释放,如消息系统、数据库等。内存池系统的大小是动态的,如果需要还可以通过从内存分区或堆空间分配用户自定义的新空间实现自动增长。
8. POSIX内存管理
VxWorks提供各种POSIX内存管理功能。包括:
- 使用calloc()、malloc()、realloc()和free()实现动态内存分配;
- POSIX内存映射文件(_POSIX_MAPPED_FILES选项);
- POSIX共享内存对象(_POSIX_SHARED_MEMORY_OBJECTS选项);
- POSIX内存保护(_POSIX_MEMORY_PROTECTION选项);
- POSIX内存锁(_POSIX_MEMLOCK和_POSIX_MEMLOCK_RANGE选项);
此外,VxWorks还支持匿名内存映射,该功能不是POSIX标准中的功能,而是作为一个扩展功能实现的。
POSIX内存管理API
由VxWorks提供的POSIX内存管理API确保了应用程序的可移植性。需要注意的是,VxWorks的POSIX内存管理功能是基于实时操作系统实现的,需要具备确定性、占用内存空间小、可扩展性的特点。在通用操作系统中常见的功能,如按需分页、写时拷贝等,在VxWorks中都不支持。这就确保了系统具有确定的内存访问与执行时间,但是也意味着系统内存将限制一个进程可以映射的虚拟内存大小。有些函数仅为了可移植性而提供,被没有进行具体的实现。
MamLib与shmLib中的函数如下所示:


9. 内存映射机制
VxWorks为内存映射文件、共享内存对象、匿名内存映射、设备内存和共享数据区域,提供了内存映射机制。
这些机制包括:
- 内存映射文件:使用mmanLib的POSIX机制;
- 共享内存对象:使用mmanLib和shmLib的POSIX机制;
- 匿名内存映射:VxWorks对使用mmanLib的POSIX内存映射的扩展,需要使用匿名标志;
- 设备内存:VxWorks使用mmanLib、devMemLib的POSIX内存映射的扩展;
- 共享数据区域:使用sdLib的VxWorks机制。
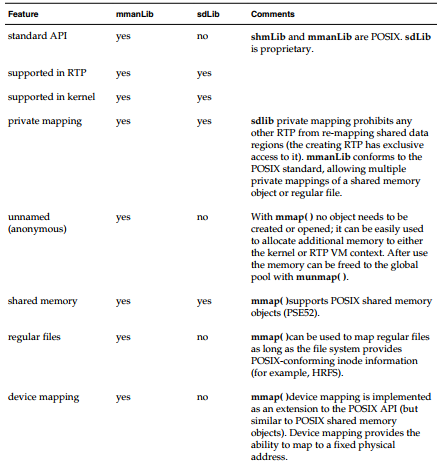
下表对基于POSIX(mmanLib)的功能与扩展、专有的(sdLib)内存功能进行了比较。它们在功能上有重叠。


POSIX内存映射文件
VxWorks提供POSIX内存映射文件支持。为了实现内存映射文件,字啊一个POSIX兼容的文件系统中打开一个常规文件时,需要将文件描述符传递给mmap()函数。同时支持共享与私有的映射。在VxWorks中需要配置INCLUDE_POSIX_MAPPED_FILES组件,以使用该功能。
对于内存映射文件,系统不会自动进行同步。同时对于mmap()和文件系统,并不存在统一的缓冲区。这就意味着应用程序需要使用msync()函数去同步文件存储介质中的映射镜像。唯一的例外就是显示地使用munmap()函数,或者在进程结束时隐式地关闭映射。在这种关闭映射的过程中,将会自动执行同步过程。
POSIX共享内存对象
VxWorks提供POSIX共享内存对象支持。通过这种类型的映射,mmap()所使用的文件描述符由shm_open()函数提供。同时支持共享和私有映射。这种类型的映射由两种内核组件提供:一个虚拟文件系统shmFs,提供了shm_open()、shm_unlink()函数;用于映射文件的mmap()扩展。这两个机制分别由INCLUDE_POSIX_SHM_和INCLUDE_POSIX_MAPPED_FILES组件提供。
共享文件系统为共享内存对象提供了名字空间。它是一个虚拟文件系统,不支持读写操作。共享内存对象的内容可以通过它们的内存映射镜像进行修改。
匿名内存映射
匿名内存映射是POSIX内存映射API的一个VxWorks扩展。它为进程提供了一个简单的获取和释放额外内存页的方法,而不需要将映射与一个命名的文件系统对象相关联。匿名内存映射仅支持私有映射。
当VxWorks中提供了RTP支持时,将自动引入匿名内存映射。必须使用INCLUDE_MMP组件,以提供内核支持。
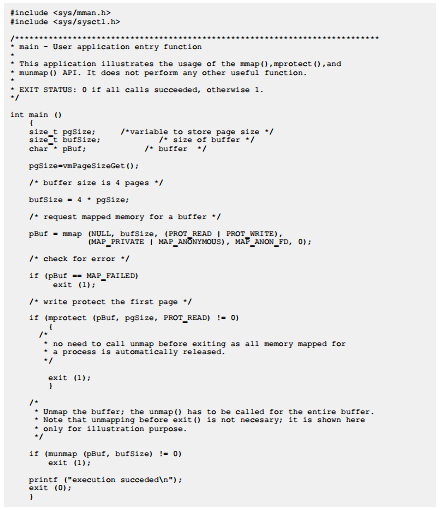
下面的RTP应用示例展示了如何使用匿名标志(MAP_ANONYMOUS)的mmap()、mprotect()和unmap()函数。内核应用程序也应该使用相同的代码,只是main()函数应该使用其他名字。
设备内存对象
VxWorks为内存映射文件机制提供了一个非POSIX的扩展,它允许获取设备内存,可以用于任何设备驱动(串口、网络、图像等等)。该机制由INCLUDE_DEVMEM组件提供。
内核函数devMemCreate()、devMemOpen()、devMemUnlink()可以用于创建、打开和删除一个设备内存对象。mmap()函数用于在设备内存对象创建或打开后执行内存映射。所以供mmap()使用的文件描述符由devMemOpen()函数提供。
共享数据区
专有的共享数据区机制为RTP应用程序互相共享一个内存区域提供了一种方法。
10. 内核虚拟内存管理
VxWorks可以针对处理器的MMU配置架构独立的接口,以提供虚拟内存支持。
该支持包括以下特性:
- 在启动时设置内核内存环境; 将虚拟空间的页映射到物理空间; 基于页空间设置cache属性; 基于页空间设置保护属性; 设置一个页映射为有效或无效; 为内存页锁定或解除TLB条目; 使能页优化;
VM支持的可编程元素有vmBaseLib库提供。
配置虚拟内存管理
如下组件提供了基本的虚拟内存管理功能。

配置内核虚拟内存环境
内核虚拟内存环境将在启动时根据BSP中提供的配置参数自动创建。
通常不需要修改默认配置,然而如果类似以下情况则可以进行修改:
- 系统中添加了新的设备或驱动;
- 某个条目的保护或Cache属性必须修改。例如,VxWorks从未向Flash写入数据,那么flash存储空间可以设置为只读。然而,如果使用Flash驱动(如TFFS),那么保护属性需要设置为可写。
- 在表中存在未使用的条目。通常,最好仅保留真正描述系统的条目,因为每个条目都可能需要额外的系统RAM空间。内存块映射的越多,页表所需的内存也就越多。
采用编程的方法管理虚拟内存
略
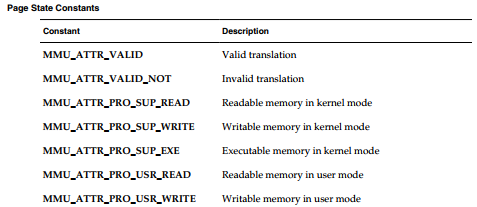
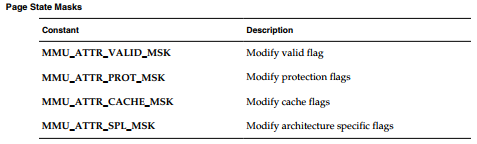
修改页状态
每个虚拟内存页(通常4KB)都有与之相关的状态属性。一个页可以是valid/invalid,readable,writeable,executable,或cacheable、non-cacheable。
页的状态可以使用vmStateSet()函数修改。下表中描述了可供vmStateSet()使用的页状态常量与页状态掩码。页状态掩码必须用于描述哪些标记位被修改了。可以使用逻辑或操作符操作页状态和掩码,以定义映射保护与cache属性。

将内存设置为不可写
内存区域可以使用vmStateSet()函数设置为写保护,从而避免无意的访问。比如,可以用于限制对某个函数中的一个数据的修改。如果一个数据对象是全局的且只读,那么任务只能读取它而不能修改它。任何必须要修改这个对象的任务,需要调用相关的函数执行修改操作。在这些函数中,数据将设置为可写,当函数退出后,该内存将被设置为MMU_ARRT_PROT_SUP_READ。
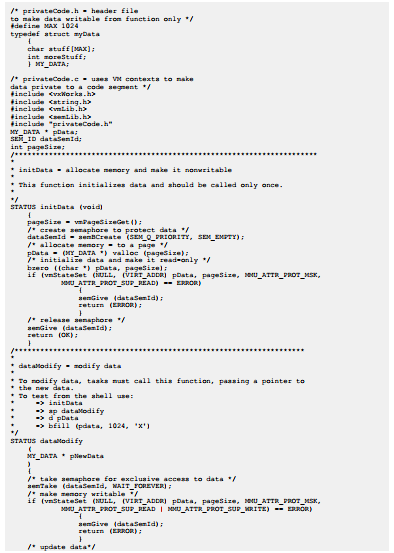
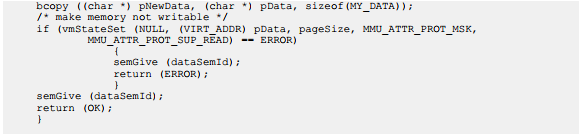
不可写内存示例
在示例代码中,一个任务调用dataModify()去修改由pData指针指向的数据结构。该函数首先使该内存可写,然后修改数据,最后将其设置为不可写。如果一个任务随后尝试直接修改数据,而不使用dataModify()函数,那么将产生一个数据访问异常。
使内存页无效
使用vmStateSet()函数,可以基于页使内存无效。任何对无效页的访问都将产生异常,无论是读或写操作。为了再使页生效,同样使用vmStateSet()函数。例如:
vmStateSet (NULL,address,len,MMU_ATTR_VALLID_MSK,MMU_ATTR_VALID_NOT);
vmStateSet (NULL,address,len,MMU_ATTR_VALLID_MSK,MMU_ATTR_VALID);
查看TLB条目
有些处理器可以将TLB中的某些条目强制永久保留在TLB中。如果特定架构的MMU库支持该特性,那么就可以使用vmPageLock()函数将这些页条目上锁,使用vmPageUnlock()函数解锁。
INCLUDE_LOCK_TEXT_SECTION组件提供了TLB锁机制。当VxWorks中包含了该组件,则系统启动时将自动把内核镜像的代码段锁定。
该功能可以用于类似cache锁定的性能优化。当常用的页条目被锁定在TLB中,TLB缺失的次数将会减少。需要注意的是,所有处理器类型对TLB条目的数量都要进行限定,否则如果锁定的条目太多,则会导致对其他动态使用的TLB条目的竞争。
页大小优化
对于一些处理器,可以使用比默认页大小(由VM_PAGE_SIZE定义)更大的大小,用于具有相同内存属性的大的、连续的内存块,并满足虚拟与物理地址对齐需求。使用该优化具有如下好处:
- 减少用于映射内存的页表项,从而降低内存使用;
- 更高效地使用TLB,减少TLB缺失,从而提高性能;
对于32位VxWorks,可以通过配置INCLUDE_PAGE_SIZE_OPTMIZATION组件,实现在启动时完成对整个内核内存空间(包括I/O块)的优化。也可以在运行时使用vmPageOptimize()函数完成页大小优化。64位VxWorks与32位类似。
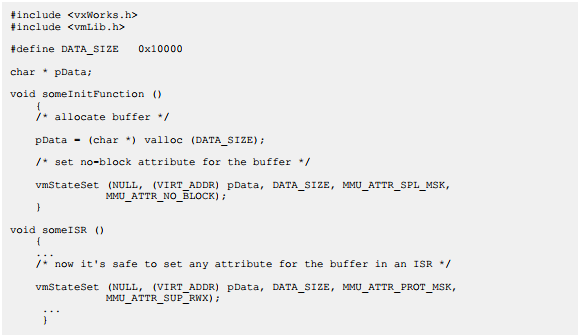
在ISR中设置页状态
对于多数处理器,vmStateSet()函数是一个非阻塞函数,因此可以在ISR中调用。然而,在某些情况下可能导致阻塞,如支持页大小优化的处理器。
为了确保ISR能够针对特定的页而调用vmStateSet()函数,这些页必须设置MMU_ATTR_NO_BLOCK属性。示例代码如下:
问题定位
如下函数与命令可以用于虚拟内存问题定位:

