简介
Ampere目前是一家专注于服务器设计的芯片研发公司,主要是ARM架构,目前该公司产品已经在一些大厂商用,本文主要简单分析一下该公司的AmpereOne系列的微架构,采用ARM架构,5nm工艺,最高3.7GHz,最多192核。各项参数都处在一线的水平,并且据说商业反馈比较好,所以就介绍一下这个系列的微架构。
微架构
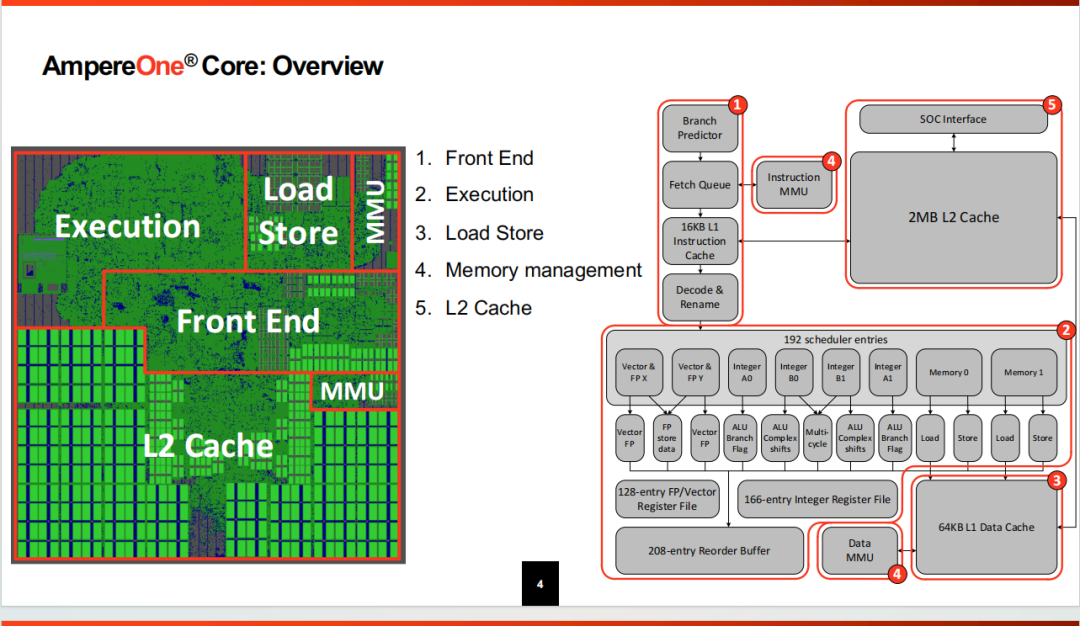
从版图上看,L2 Cache占据核相当大的面积,目前多数核都是如此,因为L2基本都是2MB的大小了。MMU是指令测和数据侧完全分开,这种微架构设计也挺主流,也有仅TLB分开的设计,ARM的一些大核设计目前来看还是混合为主。其它每看到太多特色的东西。
前端
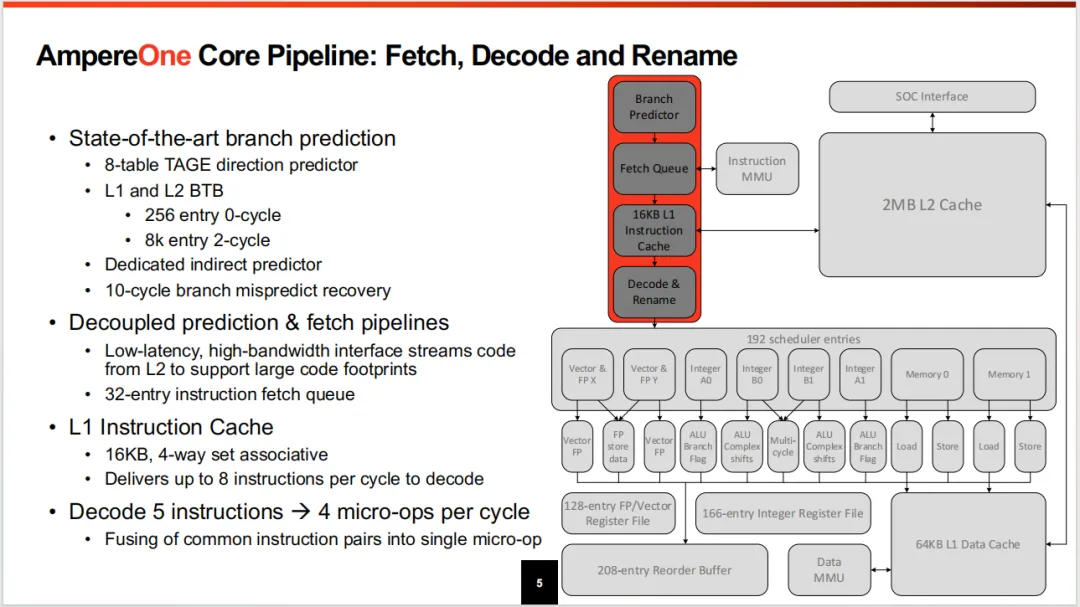
前端直接预测器使用8-table的TAGE算法,目前8-table在大核中比较主流了。BTB方面L1的0气泡是256entry,没有说是什么结构,我猜测全相联可能性不大,但依然可能是DFF做的,也不排除SRAM,这个核的工艺是5nm,时序方面应该不错。L2 BTB是8Kentry,2-cycle延迟,这里延迟保持的比较小。
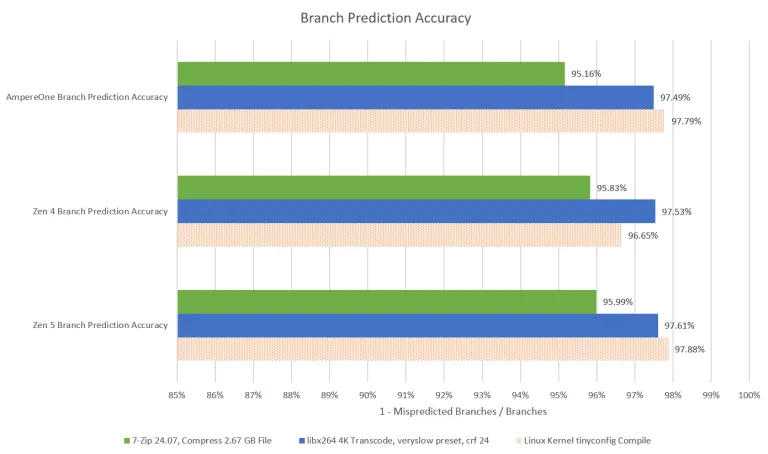
分支预测精度方面和Zen5相比差距不大,仅在压缩场景和Zen有一定的差距。但请注意,这里的工作负载没有那么大,比较单一,数值仅能简单参考。Zen5对预测器投入的资源比较大,因为Zen5的L1 BTB是8K entry和Ampere的256相比不是一个数量级,所以预估在一些复杂场景,Zen5优势会明显点。仅孤立的谈论预测器性能,Zen5在几个场景表现更优秀一点。
间接预测器不清楚什么参数,但做了单独的结构。值得关注的是,分支预测惩罚是10-cycle,这是目前我见过的大核中明确谈论的数值中最小的,这个参数对大核来讲是个挺重要的性能点的。之前聊的SIFIVE(搞RV架构)在PPT的图中显示分支错误惩罚是10-11cycle,但没有明确说。能将频率最高跑到3.7,还能保持这么低的分支预测惩罚,说明设计水准较高。
指令侧是16KB,4路组相联结构,这个设计很有意思,这里相比较ARM的一些配置比较低,即使是他们自己的另一款微架构Altra也是典型的64KB大小指令缓存。不清楚是预取做的太好还是L2延迟优化比较好的原因。也不排除这是面向服务器的,堆的核数量都是100以上,单个核指令集变化度没有那么大的原因。还有可能是因为分支预测惩罚做的很低(10cycle),导致对Cache的访问无法接受更高的延迟,这里用更小的Cache来掩盖分支预测错误的惩罚延迟(压低流水线级),这种可能性也比较大。也可能都有,原因不孤立,总之是个设计的折中,最终也是看架构师想要什么目标。我更倾向于第三种原因是主要因素,因为从预测器结构来看架构师很重视分支预测惩罚的cycle数。目前很少看到大核做这么小的指令Cache了,分支预测器目前业内没有特别大的突破,改变一下思路可能豁然开朗。但是呢,如果指令频繁MISS的场景,指令预取和L2延迟就太重要了,否则可能适得其反,总之一个不那么典型的设计需要更多的优化才能达到目标。不能因为降低分支惩罚延迟而导致前端成为瓶颈,这个核应该不会,因为前端瓶颈很好测出来,我个人认为这个设计应该比较成功,符合我对CPU微架构发展的预期。
5路decode每个周期4uop,带有指令融合技术,没有设计uop cache,这里的流水线目标已经很低了,不选这个结构也挺合理的,一般能加大带宽或者这附近流水线可以降低到很低水平,uop cache都没有太大必要,ARM应该是带宽足,这个应该是流水线做的很少。
执行
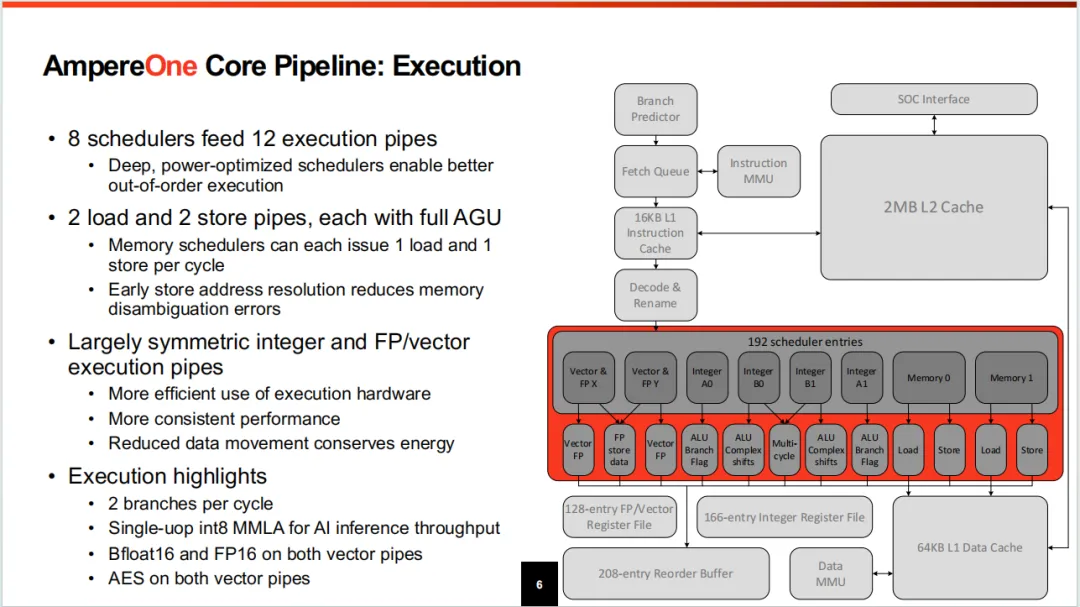
8个调度器分配给12个执行流水线,2Load,2Store流水线,这里没有做过相关内容,仅从几行文字看不出好坏。
LSU
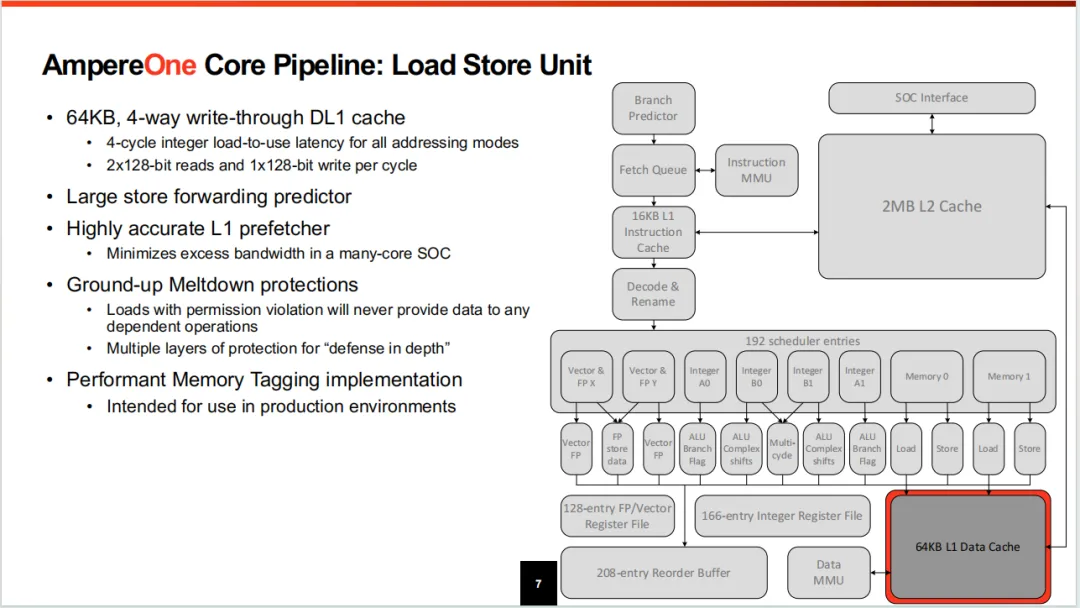
LSU看这个参数和ARM的V2/V3差点意思,64KB的4路组相联,数据带宽似乎做的一般。有外网描述:在LOAD包含在先前STORE中的情况下,可进行快速转发(延迟时间为6-7个周期)。STORE的延迟大概6-7周期,向量STORE大概12周期,这些延迟都有点高。在内存安全性上例如内存TAG在此微架构上也有应用。
MMU
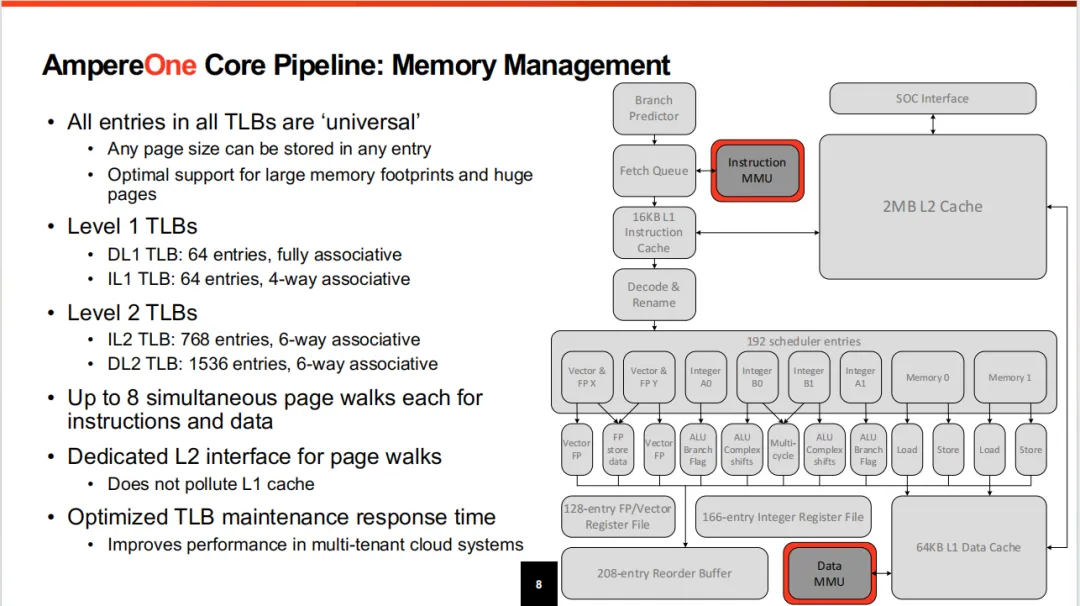
这个模块的微架构之前写过不少文章都有提及,本次简略写。L1 ITLB是64entry,4路,L1 DTLB是64全相联。L2 TLB指令侧和数据分开,从版图上看,MMU都是分为数据和指令2个不同部分。最多有8个同时运行的page walk,这个配比也是相对常规的,目前至少也是4个同时的page walk。获取PTE是直接从L2而不是从L1来避免占用Cache空间。具体的一些参数大家参考下表,关于MMU的微架构设计我在多个文章都描述过相关设计的权衡。

L2
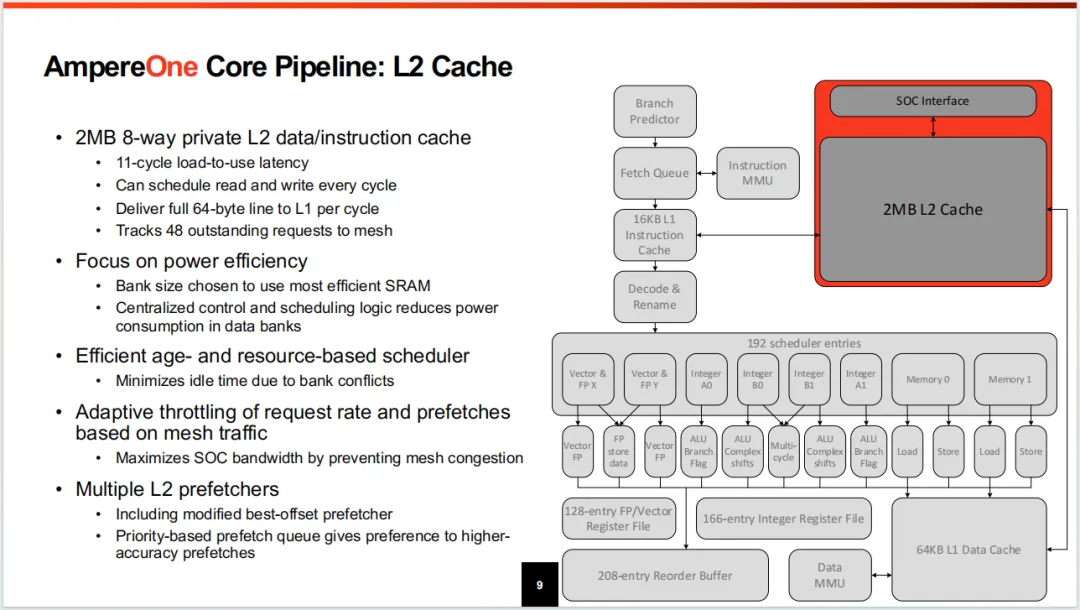
二级缓存目前看到的大核常见的配置是2MB,延迟11个周期,每周期可以同时执行一次读写。宣称可以一个周期回填64B到L1。像其它参数大家参阅图片。
总结
这个核压低分支预测惩罚我觉得是个亮点,像执行以及L2部分内容以后有机会再讨论。
