1 简介
Wind River 公司推出的 VxWorks 系统是过去十年来非常成功的一款实时操作 系统。与桌面/服务器操作系统的复杂性相比,VxWorks 操作系统结构的相对简单性使其成为开发嵌入式系统的最佳选择。但随着现代嵌入式系统软件的日益复杂,加上对其可靠性和适用性的预期不断提高,开发人员需要一种更高级、更灵活而且功能全面的操作系统,以构建面向未来的嵌入式系统。
QNX® Neutrino® 实时操作系统的第三代架构和尖端技术为开发人员提供了开发未来平台软件的途径。嵌入式系统的开发人员现在能使其产品具有与高级操作系统一样的复杂功能,同时又能精确响应嵌入式系统环境的独特需求。QNX Neutrino 可在 ARM、MIPS、PowerPC、SH-4 与 x86 平台上运行。
传统意义上,从实时操作系统(如 VxWorks )向高级操作系统(如 QNX Neutrino)移植应用程序并不容易。需要考虑可能出现的各种问题以及进行的各种选择可能对移植过程产生深远的影响。认识到这种情况后,QNX 开发了功能全面的迁移工具(包括本文件)和移植 Library 库,帮助客户以更可控的方式将其基于 VxWorks 的应用程序移植到 QNX Neutrino 实时操作系统中。
本文重点介绍了确立移植方法的影响范围以及您需要做的决策。如果把移植过程看作一次旅行的话,那么本文就是行程路线图。尽管某些移植可实现自动化,但从 VxWorks 向 QNX Neutrino 移植是仅使用自动化工具无法完成的复杂过程。要知道需要完成什么工作以及如何完成,必须先理解两种操作系统的区别。虽然本文全面介绍了与移植过程有关的所有重要主题,但无法对这一复杂的专题进行详尽论述。必要时,您可参考其它 QNX 文件以深入了解该专题。
本文涉及到应用程序开发/移植的各个阶段,并对两种操作系统进行了对比。它阐述了移植策略并指出了两种操作系统之间的主要异同点。
我们使用“分层”法介绍了程序移植每个阶段的移植要求,包括从初始化开始,到构建目标硬件,然后以多少具有硬件独立性的高级应用程序结束。除概括介绍移植要求之外,本文还对 QNX Neutrino 与 VxWorks 的应用程序接口 (API) 进行对比,证明 QNX Neutrino 应用程序接口是 VxWorks 应用程序接口的真正超集。
最后,本文还介绍了 vx2qnx 移植库,当向 QNX Neutrino 移植 VxWorks 应用程序时,它能帮助开发人员最大限度减少对原始程序代码的修改。虽然在多数情况下,应用程序会很复杂,以致需要修改源代码才能将其完整地移植到 QNX Neutrino 系统中,但该移植库实现了 VxWorks 的关键功能,因而能确保开发人员按阶段移植程序。由于该移植库是以源代码的形式提供的,因此它也是一种极佳的参考,可让客户清楚如何扩展移植库以获取其所需的其他功能。
注意:本文中的“VxWorks”在所有情况下均指代 Wind River 公司的 5.x 版产品组合,而不是指其 AE 产品。
1.1 架构概述
本部分着重介绍两种操作系统架构之间的主要区别,以及在向 QNX Neutrino 移植应用程序时要解决的主要问题。第 2 节提供了更为详尽的分析。
1.1.1 架构对比
1.1.1.1 VxWorks
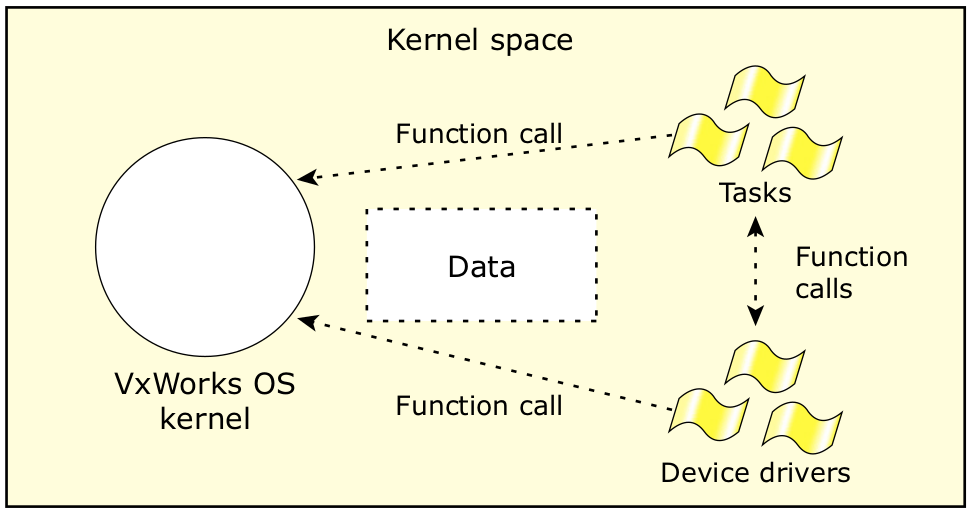
图1:VxWorks 系统的架构。
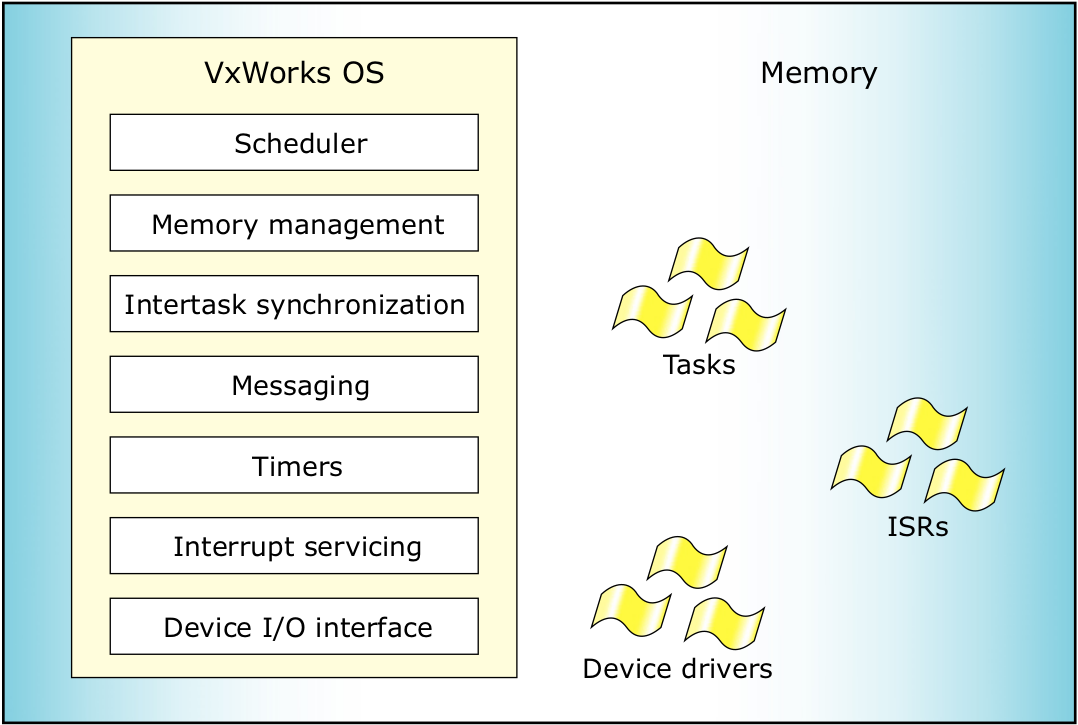
图 1 显示的是系统架构示意图。VxWorks 内核很小,除含有调度程序外,它还具有内存管理、任务间同步、信息发送、计时器、中断服务、输入/输出设备接口等功能。操作系统内最小(而且唯一)可调度的单元是任务。
操作系统通过使用信息发送和同步技术监视任务的执行情况。可抢占式内核会使用基于优先级的调度程序决定任务应何时执行。操作系统和所有任务都位于同一个公用地址空间;所有任务都会以内核模式运行,以完全访问所有处理器指令和物理内存(包括内核内存)。
虽然操作系统的处理器上不需要内存管理单元 (MMU),但在执行指令和数据高速缓存(如需要)时可能需要使用它(如有)。内存管理单元是以任务访问内存时使用物理内存地址的方式建立的。也就是说,无需内存地址转换以从任务内使用的内存地址中获取物理地址。需要重视的是,尽管VxWorks 可启用内存管理单元,但它不提供任何内存保护功能。
任务与操作系统内核之间的通信是通过一个简单的函数调用接口完成的,该接口可能会(也可能不会)对参数进行严格的错误检查。虽然速度很快,但如果不注意确保参数的正确性,这种机制就可能导致内部内核参数受损。
中断服务例程 (ISR) 与设备驱动器(由 Wind River 或用户提供)是通过调用适当的应用程序接口嵌入操作系统的。启用的设备驱动程序的应用程序接口可确保使用标准的输入/输出调用(打开、读取、写入等)访问设备。设备驱动程序也可完全访问可用的内存空间。
1.1.1.2 QNX Neutrino 架构
QNX Neutrino 是一种基于微内核且具有微内核结构的操作系统,它能提供一组协作进程所需的最少服务,确保它们提供更高级的操作系统功能。 QNXNeutrino 还是一种基于进程的多线程操作系统,它能实现操作系统服务,例如可通过 QNX Neutrino 微内核管理的信息发送基元与同步基元互相通信,以及与应用程序通信的受内存保护的用户进程。
这种架构与传统的实时执行程序和单核 Unix 式系统有本质的区别。QNX Neutrino 微内核与标准实时执行程序在如何使用进程间通信 (IPC) 服务,并通过附加的服务进程扩展内核功能方面有显著区别。由于操作系统是以微内核管理的一组协作进程的形式实现的,因此用户编写的进程可同时用作应用程序,以及(针对与用户有关的程序)扩展底层操作系统功能的进程。 因此,操作系统本身就变为“开放”式的,而且易于扩展。
另外,用户编写的操作系统扩展组件不会影响核心操作系统的基本可靠性。QNX Neutrino 充分利用处理器的内存管理单元在受保护的运行环境中提供完整的可移植操作系统接口 (POSIX) 进程模型。微内核可为用户应用程序和操作系统组件(设备驱动程序、文件系统等)提供完整的内存保护功能。
为嵌入式应用程序,特别是任务关键型系统增加内存保护功能能实现的主要优势是提高系统的稳定性。如果在多任务处理环境中运行的某个进程试图访问未明确声明或分配用于其访问类型的内存资源,内存管理单元硬件就能利用内存保护功能通知操作系统,由其(通过失败/冲突指令)中止线程。这样可以在进程地址空间之间提供“保护”,防止一个进程中出现的 线程编码错误“损坏”其他进程(或操作系统)中的线程使用的内存。这种保护对系统开发和安装的运行系统都很有用,因为它允许进行事后分析。
在开发过程中,常见的编码错误(如指针越界和超过数组边界的索引)可导致一个进程/线程意外覆盖另一个进程的数据空间。如果不能立即引用覆盖的内存,那么调试会十分困难。启用内存管理单元后,操作系统就能在出现非法内存访问时立即中止进程,为程序员提供即时反馈,而不是一段时间之后莫名其妙地导致系统崩溃。操作系统还能提供失败进程中错误指令的位置或该指令相关的符号调试程序的位置。
图2:QNX Neutrino 架构提供全内存保护。
在宏内核架构中,“内核”具有许多功能,几乎相当于整个操作系统,而 QNX Neutrino 是名副其实的微内核系统。它不仅小巧精致,而且只专门提供几种基本的系统服务,包括处理线程、信号、信息发送、同步、调度、计时器和进程。与线程不同,QNX Neutrino 本身不会被安排执行任务。只有在线程进行明确的内核调用或响应硬件中断时,处理器才会执行内核代码。整个操作系统都是在这些调用的基础上构建的。QNX Neutrino 是一种完全可抢占式内核,即使在进程间传递信息时也一样;它会在抢占前重新恢复中断的信息传递。
QNX Neutrino 微内核的最小复杂性可为通过内核的不可抢占的最长代码路径设置上限,其紧凑的代码大小允许对复杂的多处理器问题进行跟踪。加入微内核服务的选择依据是较短的执行路径。需要进行大量工作(如进程加载)的运行会被分配到外部进程/线程,与为满足请求而在线程内完成的工作相比,进入该线程的上下文所付出的努力可谓微不足道。
系统进程与用户编写的程序在本质上很难区分——因为它们都使用相同的公共应用程序接口和任何(有适当特权的)用户进程都可使用的内核服务。由于多数操作系统服务都是标准系统进程提供的,因此增大 QNX Neutrino操作系统本身很简单:只需编写新程序提供新的操作系统服务即可。
1.1.1.3 操作系统对比
VxWorks 中的基本运行单元是任务。QNX Neutrino 中的基本运行单元是线程。QNX Neutrino 中的线程会集中进入名为“进程”的容器内,并通过操作系统进行控制和调度。VxWorks 中的任务与 QNX Neutrino 的线程是一样的。VxWorks 中的任务控制是使用 taskLib 函数实现的,而 QNX Neutrino 中的线程控制是通过 pthread_函数族实现的。
VxWorks 中只有一个“任务容器”,即操作系统本身。在 QNX Neutrino 中,可执行含有一个或更多线程的多个进程。每个进程都有自己专用的受保护的并且其他进程无法访问的内存空间。在这种情况下,完整的 VxWorks 系统相当于在 QNX Neutrino 中运行的具有许多线程的独立进程。在 VxWorks 中,每个任务都能完全访问处理器提供的整个物理内存空间。也就是说,每个任务都能访问(也可能破坏)属于另一个任务或操作系统的内存空间。进程可共享内存区,但进程必须使用函数 shm_* 明确指明其想要共享的内存区。
QNX Neutrino 中的操作系统和应用程序之间有非常清楚的界限。进入操作系统的调用是通过能完全隔离用户应用程序和操作系统的系统调用接口实现的。这与 VxWorks 提供的基于函数的操作系统接口形成了鲜明对比,因为其中的参数错误或非法内存指针会导致操作系统内部结构的损坏。
应用程序与操作系统的这种分离在建立用于目标系统的应用程序加载时也是显而易见的。在 VxWorks 中,操作系统组件必须链接到应用程序中,以产生单独的最终映像。在 QNX Neutrino 中,应用程序是以完全独立于内核的方式建立的,并单独储存在文件系统中以便随后执行。用户无法修改QNX Neutrino 内核,由于其具有可扩展的架构,因此也无需修改。在 QNX Neutrino 中,用户可通过向其他协作进程发送信息来扩展内核的功能。
VxWorks 中的内存访问几乎总是按照“一对一”映射的方式进行的,其中的物理内存地址与应用程序的地址完全相同。QNX Neutrino 启用了虚拟内存;内存管理单元会将应用程序地址转换成对应的物理内存地址,同时将适当的内存保护标准用于被访问的内存。如果需要访问一个特殊的物理内存位置,必须使用函数调用 mmap_* 将内存空间“映射”到进程内存空间。如果需要知道应用程序的物理地址(如要将缓冲库位输入硬件设备),就需要使用函数(如 mem_offset()、 mmap_device_memory()、 mmap_device_io() 和 mmap())转换地址。
QNX Neutrino 在线程中加入了“特权”和“许可权”概念。这在本质上提供了一种可限制线程使用的功能的机制。例如,在 x86 架构中,线程必须具有输入/输出特权(通过使用函数 ThreadCtl() 取得)和根许可权(通过在应用程序映像上设置适当的许可位取得),然后才能访问输入/输出操作码。其他处理器族中也提供了类似的特权级别。
由于两种操作系统的基本架构各异,因此与每种系统中的设备驱动程序集成有关的中间件也有明显区别。所有类型的设备(块设备、字符设备、网络设备等)都是如此。
1.1.2 首要移植问题
由于两种系统有所区别,因此您需要解决以下关键问题:
- VxWorks 与 QNX Neutrino 的程序库应用程序接口有很大差异。虽然两种操作系统都符合可移植操作系统接口 (POSIX) 标准,但它们都有许多各自独有的库例程。因此,必须将每个 VxWorks 例程“映射”到相同的QNX Neutrino 例程中。
- 必须将应用程序地址转换成物理内存地址。需要将物理内存明确地映射到进程的内存空间。
- 在 QNX Neutrino 中,不同进程中的线程之间不会自动共享内存。必须在不同进程中的线程之间明确地启用共享内存。首先,进程只能访问堆/操作系统分配给它的内存。
- 由于设备驱动程序的基础结构有很大不同,因此无法重用设备驱动程序代码;大部分驱动程序都需要重新编写。设备驱动程序必须处理适当的特权、优先权和地址转换问题。
1.2 移植策略
从移植代码的角度看,用户可遵循两种可能的策略:
- 使用能在 QNX Neutrino 上模拟 VxWorks 应用程序接口的 vx2qnx 移植库,以最少量的修改将大部分应用程序代码从 VxWorks 迁移到 QNX Neutrino。
- 使用适当的 QNX Neutrino 私有 调用替换 VxWorks 私有函数。这种替换可通过手动方式完成,或通过使用代码分析工具自动完成。由于某些VxWorks 函数与本机 QNX Neutrino 应用程序接口之间不存在直接映射,因此需要对一部分应用程序代码进行重新架构和修改,以适应 QNX Neutrino 提供的架构与服务。
第一个方案的目标是尽可能以最少量的修改将应用程序从 VxWorks 迁移到QNX Neutrino。最理想的是,能使这种迁移像“重建并运行”一样简单。但在实际中,多数应用程序都很复杂,而且操作系统架构存在很大差异,因此无法在实际操作中实现完全模拟。同时,常见的操作系统中还有数百种应用程序接口功能。因此,正确地模拟所有 应用程序接口功能不仅困难而且容易出错。
第二种方案要求从 VxWorks 向 QNX Neutrino 移植应用程序,这涉及到修改一部分代码以体现 QNX Neutrino 提供的新架构与服务。这样您就不必再通过 VxWorks 进行编码就能不断取得进展,以开发能使用 QNX Neutrino 中更多可用功能的编码。对更改进行“手动编码”还具有性能上的优势。而耗时和冗长的转换过程是明显的不利因素。同时,为充分利用 QNX Neutrino 的功能集,您还需要对应用程序进行重新架构。
两种方案都需要 VxWorks 私有函数 到 QNX Neutrino 私有函数调用的适当映射。每种函数均适应以下四种广泛类别之一:
- 无需更改(如标准输入输出函数和 POSIX 函数)
- 函数语法更改(一对一映射)
- 必须在 QNX Neutrino 中模拟函数调用(必须使用若干 QNX Neutrino 功能以模拟 VxWorks 功能)
- 不存在相同功能。
映射时必须小心,以确保映射例程以同样的方式运行,或确保其运行的差异性在应用程序看来不会如此明显。
vx2qnx 移植库可模拟常用的 VxWorks 功能(如任务库功能、信号量、信息队列等)。由于开源移植库已经指明并且其他第三方提供的资源也已确认,因此在 POSIX 操作系统(如 QNX Neutrino)上开发基本 VxWorks 应用程序接口模拟是一种相对畅通无阻的任务。这种移植库是以源代码的形式提供的,因此开发人员能轻松地对其进行扩展,以增加应用程序接口的覆盖范围。但我们还必须考虑移植库能提供的兼容程度。特别是,移植库可能无法处理需要直接访问硬件的代码(因为这种代码依赖于相同的物理和虚拟地址,而且可能需要服务中断)。因此必须对大多数“接近硬件”的代码进行手动移植,以确保将其正确集成到 QNX Neutrino 架构中。
VxWorks 中的 VxSim 产品可识别能以这种方式移植的应用程序部分和需要进行深入工作才能移植的程序部分之间的明显区别。最理想的是,使设计的应用程序在两种目标硬件和VxSim 上运行,因此您应该使用 vx2qnx 移植层在 QNX Neutrino 上“重建并运行”应用程序。
对于某些应用程序,可结合使用两种策略。可使用 vx2qnx 移植库完成大部分的初始移植,并通过手动编码覆盖不支持的区域。完成初始移植后,应引入一种规划策略,以尽快使用本机 QNX Neutrino 代码,这样就能实现QNX Neutrino 的全部功能集并在必要时进行优化。
从执行的角度看,也有两种可用策略:
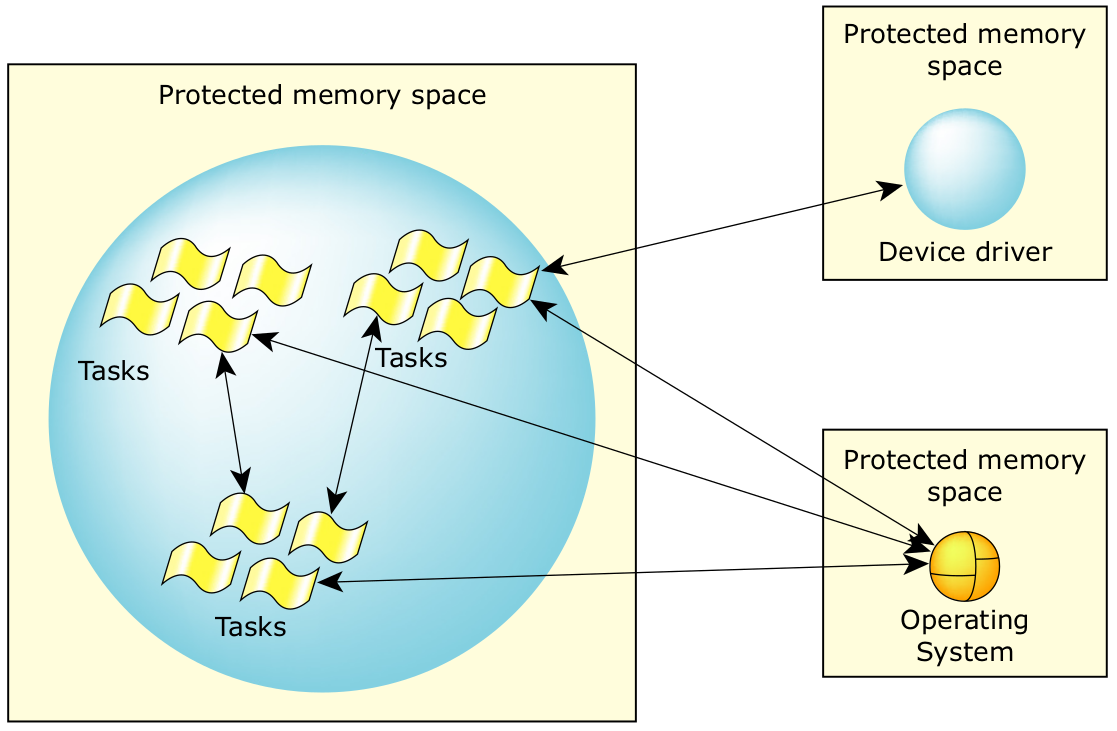
1. 让应用程序作为单独的多线程进程在 QNX Neutrino 中运行,如图 3 所示。
图3:QNX Neutrino 中单独的多线程进程。
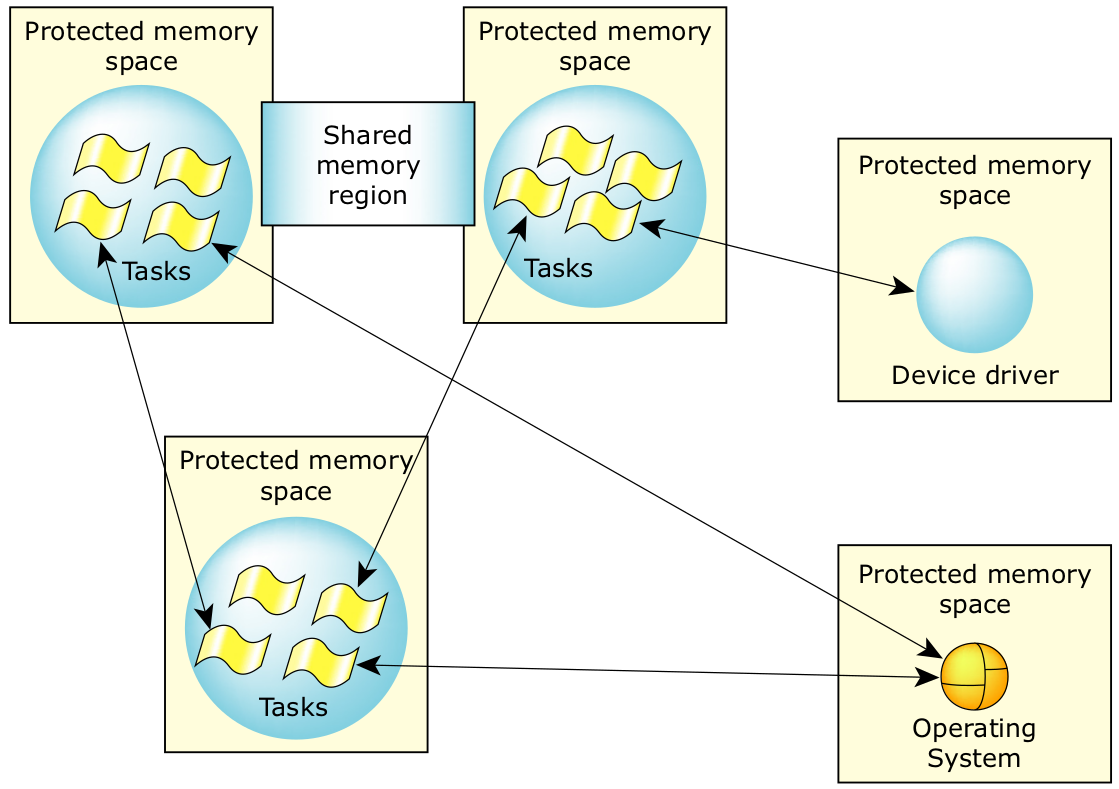
2. 将应用程序分成 QNX Neutrino 中的多个多线程进程,如图 4 所示。可使用本机 QNX Neutrino 进程间通信 (IPC) 调用或共享内存区,以便进程内的线程之间进行通信。
图4:QNX Neutrino 中的多个多线程进程。
方案一具有可快速实施的优势,因为它能以更接近 VxWorks 运行模式的方式进行映射。但它具有明显的缺陷:无法使用 QNX Neutrino 提供的保护与隔离机制,防止任务意外地互相破坏。虽然不是最理想的方案,但与 VxWorks实现相比,这种机制仍能提供充分保护,因为 QNX Neutrino 及其本机设备驱动程序受到全面保护。
方案二更令人满意,但其需完成的工作量更大。它能实现 QNX Neutrino 提供的完全保护和隔离功能。但除了重新编写之外,很可能还需要对代码进行重新架构,以支持本机命令集。
在实际操作中,最好是先根据方案一进行初始移植,然后以方案二为目标逐步完成移植。可使用本机 QNX Neutrino 或针对进程间通信的 vx2qnx 移植库调用随时从主应用程序进程中“取出”松散耦合的 VxWorks 任务,并将其放入单独的进程中。清晰的进程间通信接口就是为松散耦合的任务设计的(如信息队列或使用信号量保护的定义的共享内存块)。强耦合任务 可包含使用共享函数回调或针对进程间通信/同步的全局变量的任务。这种分离机制提供的附加模块化和隔离功能,能在针对某些问题进行故障排解时大显身手,例如解决“内存侵犯”(一个任务覆写另一个任务拥有的内存)问题时。由于应用程序的模块化程度不断提高,而且有时还需要增加新功能,因此您可以开始对一部分应用程序进行重新架构,以充分利用本 机 QNX Neutrino 函数调用。
还要注意规划一种迁移策略,以在最后尽可能使用本机调用,以优化应用程序并完全实现 QNX Neutrino 的增强功能。
1.2.1 建议移植路径
建议的移植路径可概括为以下几种:
- 使用 vx2qnx 移植库,以最少量的代码修改移植应用程序代码。必要时,需对应用程序的一部分进行手动编码,以适应新的架构。这会创建一个包含所有 VxWorks 线程的单独进程。这样就能在最短时间内启动并运行应用程序。
- 识别任何有性能问题的区域,并使用本机 QNX Neutrino 调用对这部分进行重新编写。
- 分析代码库并引入使用本机 QNX Neutrino 进程间通信机制(针对松散耦合的功能块)进行通信的分离进程(具有一个或多个线程)。
- 当需要增加新功能时,可使用本机 QNX Neutrino 函数启用这些功能,而不是在移植层中扩展代码。
2 详细对比
在本节中,我们将就特定的功能集对两种操作系统进行详细的对比分析。
2.1 内核可访问性
2.1.1 VxWorks
图5:在 VxWorks 中,所有内容都是在“内核空间”内运行的。
VxWorks 中的内核在许多层上都是可完全访问的,包括任务对它的无意访问(参见图 5)。应用程序中的所有内容本质上都是在“内核空间”内运行的。任务通过 VxWorks 程序库提供的直接函数调用获得对内核的访问权限。操作系统、任务和设备驱动程序之间的通信是使用直接函数调用实现的,并且系统内所有可执行组件都能访问所有数据区。
任务管理是通过 VxWorks 调度程序进行的。可通过一系列 taskHook 例程(位于 taskLib 内)修改任务执行的一些特征。这些包括 taskSwitchHookAdd() 、taskCreateHookAdd()、 taskDeleteHookAdd() 等函数。任务还可通过直接访问任务控制块 (TCB) 结构访问与任务有关的操作系统信息。虽然可以进行这种访问,但由于用于储存信息的 C 结构在不同的释放之间会发生变化,因此建议您不要采用这种访问。这些结构的损坏(可在显示所有任务信息时检测 到)通常由常见的用户问题所致(如堆栈溢出)。
VxWorks 中的任务调度是基于优先级的,而且可通过两种调度模式实现完全抢占:即先入先出 (FIFO) 调度和循环调度。任务控制是通过 taskLib 库完成的。可通过调用延迟任务的调度期 (taskDelay)、防止任务被抢占 (taskLock/intLock)、更改任务的优先级 (taskPrioritySet) 等。
2.1.2 QNX Neutrino
QNX Neutrino 微内核与进程管理器在单独的模块 (procnto) 内配对。所有运行系统都需要这种模块。进程管理器能创建多个 POSIX 进程(每个进程可能包含多个 POSIX 线程)。
用户进程可直接通过内核调用访问微内核功能,并通过向 procnto 发送信息访问进程管理器功能。用户进程可通过调用 MsgSendv() 内核调用发送信息。需要重视的是,在 procnto 内执行的线程调用微内核的方式与其他进程内的线程完全一致。进程管理器代码与微内核共享相同的进程地址空间并不意味着有“特殊”或“专用”接口。系统内的所有线程均共享相同一致的内 核接口,而且所有线程都会在调用微内核时进行特权转换。
2.2 可移植操作系统接口 (POSIX) 支持
VxWorks 为多种工具(包括调度、信号量、信息队列、信号和计时器)提供了 POSIX 接口。QNX Neutrino 包含所有这些接口,而且还提供了完全符合 POSIX 标准的同步机制套件,包括信号量、互斥锁、信息队列、条件变量、信号、计时器、休眠锁、读-写锁等。所有基于任务/线程的基元都符合POSIX 标准。
在 VxWorks 中,任务优先级是按照数值越小的优先级越重要的方式运行的。POSIX 与 QNX Neutrino 都采用相反的方式:数值越大的优先级越重要。QNX Neutrino 还提供了 256 种不同的优先级(与 VxWorks 类似)用于线程调度,这样就能在 VxWorks 与 QNX Neutrino 优先级之间进行直接的一对一映射。
就调度策略而言,除基于标准的循环调度与先入先出调度 (FIFO) 的策略之外, QNX Neutrino 还提供了偶发调度策略(POSIX 接口规范中也有说明),允许有偶发 CPU 利用需求的应用程序线程分配其所需的执行预算。
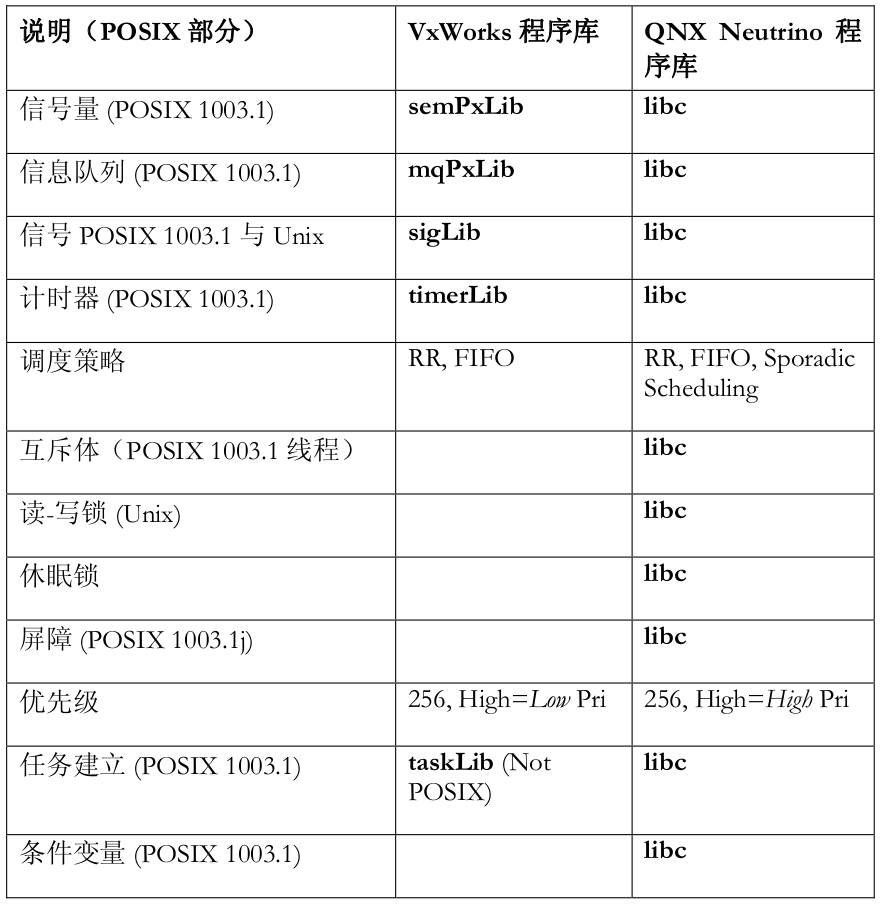
下表对 VxWorks 与 QNX Neutrino 支持 POSIX 的功能进行了并列对比。请注意,在VxWorks 中,大部分不同的功能都是由独立库提供的;在 QNX Neutrino 中,大部分POSIX 功能都是通过 libc 程序库内的函数实现的。
QNX Neutrino 启用了标准 POSIX 应用程序接口,而且符合以下标准:
- POSIX 1003.1 (系统接口)
- POSIX 1003.1 (系统接口扩展)
- POSIX 1003.1b (实时扩展)
- POSIX 1003.1c (线程)
- POSIX 1003.1b (附加实时扩展)
- POSIX 1003.1e
- POSIX 1003.1g
- POSIX 1003.1f (透明文件访问)
- POSIX 1003.1j (高级实时扩展)
- POSIX 1003.1-200x (草稿)
- POSIX 1003.4-200x (草稿)
QNX Neutrino 还符合 POSIX 1003.1-2001 规范(根据 1003.1-1996 规范修改了 P1003.1a、1003.1d-1999、1003.1g-2000、1003.1j-2000)的要求,以及现行POSIX 1003.13 文件(PSE51、52 和 53)定义的功能要求。QNX Neutrino 已获得 PSE52 实时控制器 1003.13-2003 系统的符合性认证。
2.3 内存可访问性
2.3.1 VxWorks
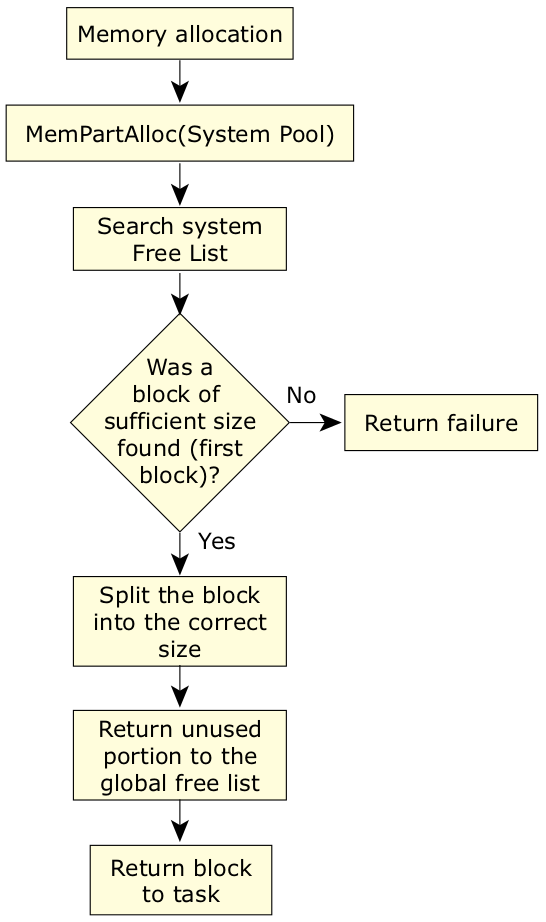
如前所述,VxWorks 中的内存空间对所有任务都是开放的,访问内存时可在应用层上使用物理地址。如果在标准实现中使用了内存管理单元 (MMU),它只会在提供指令和数据缓存功能时启动。可使用标准的库分配例程(malloc()、calloc() 等),或使用满足指定内存池(在启动顺序的内存初始化阶段建立)要求的“内存池特定”访问例程分配内存。
对于硬件设备的访问,可使用 cacheDmaMalloc()/cacheDmaFree() 例程为使用直接内存访问的设备提供缓存保护内存。尽管有时需要将“虚拟”内存转换成“物理内存”(使用cacheDrvVirtToPhys()/cacheDrvPhysToVirt() 函数),但根据架构的不同,这种转换并不常见。
内存块是使用“首次适应 (first-fit)”分配策略进行分配的,当被释放后,它会返回空闲列表(一种单向链表结构)。利用这种实现,只能在一个方向上合并相邻的空闲块。重复分配/空闲周期会很快使内存成为碎片,导致无法满足内存请求,尽管有充足的物理内存可用。在使用 C++ 程序库(如 STL)时,这种内存破碎的现象尤为突出,它常常导致需要更换与操作系统一起提供的分配器。
图6:VxWorks 中的内存分配。
2.3.2 QNX Neutrino
QNX Neutrino 提供了使用内存管理单元 (MMU) 实现的功能全面的虚拟内存。常见的内存管理单元通过将物理内存分成一些页大小为 4 KB 的物理内存来运行。处理器内的硬件会利用储存在系统内存中定义虚拟地址(如在应用程序内使用的内存地址)到 CPU 发出地址的映射的一组页表,以访问物理内存。在线程执行时,操作系统管理的页表会控制线程使用的内存地址如何“映射”到处理器附属的物理内存。
QNX Neutrino 提供了全面的内存保护模式,它能将系统映像内的所有代码重新定位到新的虚拟空间,以启用内存管理单元硬件并建立初始页表映射。这能确保进程管理器在受保护的启用内存管理单元的运行环境中启动。然后,进程管理器会接管该运行环境,并根据其启动的进程的需要更改映射表。在该模式下,会为每个进程分配由 CPU 的内存管理单元控制的专用虚拟内存。
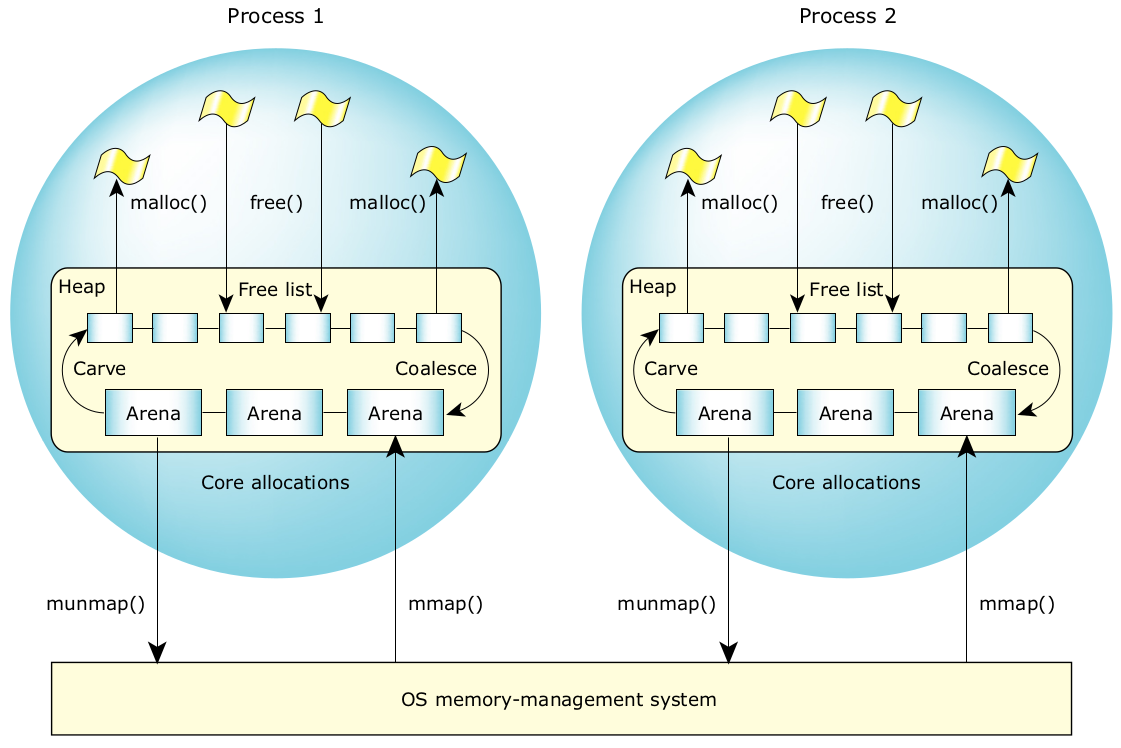
任务进行的内存分配是使用 POSIX 标准 mmap() 函数调用实现的,QNX Neutrino 在其顶部提供了默认的内存分配器。内存分配器采用包括内存池分配与合并空闲内存块(在其可用时)在内的组合技术,试图最大限度减少内存碎片并对性能进行优化。由于进程管理器是以 4 KB 为单位管理内存的,而且进程管理器能组合非邻近的物理页来满足内存分配请求,以建立相邻的虚拟区,因此物理内存碎片并不是一种常见问题(必要时,内核可对物理内存进行碎片整理)。
默认的 QNX Neutrino 分配器是基于首次适应 (first-fit) 分配策略的。每个进程都有自己的堆,因此设计完善的系统含有的堆碎片最少,因为仅限于相同进程内的线程访问堆。分配器的运行原理如下。
按“页面大小”整数倍的块形式从系统中获取内存。然后会对内存块(也称内存场)进行划分,以满足单独的内存分配请求。当应用程序请求获取内存(使用 malloc()、calloc() 或 realloc() 调用)时,系统会搜索空闲列表,寻找大小合适的内存块。
可将搜索到的第一个此类内存块用于满足这一请求。如果找到的内存块太大,它会被分成两段。第一段用于满足分配请求,剩余部分会进入空闲列表。只要有内存释放到系统中,它都会被置于空闲列表内。邻近的内存块会在空闲列表上自动合并。当完整的内存场在空闲列表上完成合并后,它会自动返回系统中。
QNX Neutrino 中的空闲列表是使用双向链表维护的。因此,可同时在两个方向上进行合并。这也显著减少了本机内存碎片问题。
图7:QNX Neutrino 中的内存管理。
QNX Neutrino 系统架构指南提供了更多有关操作系统如何管理内存的详细信息。
2.4 任务间/进程间通信
VxWorks 提供了几种不同的任务间通信机制。可使用的不同方法包括:
信号量
信号量是 VxWorks 中的任务间进行同步的主要手段。它提供了三种不同的信号量:二进制信号量、计数信号量和互斥信号量。二进制信号量用于任务间针对临界区域的简单同步。计数信号量允许对代表资源(可以多重方式获取)的临界区域进行多路同时访问。互斥信号量的特别之处在于它能针对基本信号量种类的一些内在问题(包括增加优先级反转保护、删除安全以及对资源的回归访问)提供解决方案。 VxWorks 的所有信号量还允许与获取资源有关的超时,以防止无限期等待。
当建立信号量时,程序还能为等待信号量(即将可用)的任务指定唤醒机制。有两种不同的唤醒机制可用: 基于优先级的唤醒机制可唤醒优先级最高的任务,而基于先进先出 (FIFO) 的唤醒机制会唤醒等待最久的任务(不考虑其他被阻塞任务的优先级)。 VxWorks 还提供对POSIX 信号量的访问。
信息队列与管道
VxWorks 提供了信息队列作为任务间通信的主要手段。信息队列可保留数量可变的信息,每种信息都有不同的长度。应用程序信息会使用 msgQSend函数在信息队列中排队。在有可用信息之前,接收器会一直封闭。当有可用信息时,会使用以下两种唤醒机制之一唤醒封闭的接收器。基于优先级或先进先出的机制。
VxWorks 的本机信息队列只提供了两种类似的优先级:常规优先级和紧急优先级(信息在发送时会被存放在队列开头) VxWorks 还提供了具有 32 种优先级的 POSIX 信息队列(mq_*)。
管道提供了进程间通信的另一种方式。管道提供了“选择”功能,它允许任务等待来自任何一组文件描述符(输入/ 输出设备)的数据。QNXNeutrino 提供了符合 POSIX 1003.1 接口规范要求的管道接口实现。
2.4.1 VxWorks 信息队列实例
该实例说明了如何使用信息队列在 VxWorks 中的任务之间实现同步和进行通信。首先,要建立一个会在不同任务间共享的信息队列。这样会产生四种任务:两个发送器任务和两个接收器任务。
#include "msgQLib.h"
#include "stdio.h"
#include "sysLib.h"
#include "string.h"
#include "taskLib.h"
#define MAX_NUM_MSG 5
#define MAX_MSG_LEN 100
#define NUM_MSGS 2*MAX_NUM_MSG
MSG_Q_ID msgQId;
void sendTask1(void)
{
static char buf[MAX_MSG_LEN];
int i;
for (i = 0; i < NUM_MSGS; i++) {
/* Yield to allow other tasks to run. Otherwise FIFO
means that this task will run until blocked. */
taskDelay(0);
/* Write and send a message. */
sprintf(buf, "Send1 %d", i);
if (msgQSend(msgQId, buf, strlen(buf) + 1, WAIT_FOREVER, MSG_PRI_NORMAL) == ERROR) {
printf("Send 1 msgQSend failed!\n");
return;
}
if (i == 3) {
/* Send an urgent message. */
sprintf(buf, "Send1 URG %d", i);
if (msgQSend(msgQId, buf, strlen(buf) + 1, WAIT_FOREVER, MSG_PRI_URGENT) == ERROR) {
printf("Send 1 msgQSend failed!\n");
return;
}
}
}
}
void sendTask2(void)
{
static char buf[MAX_MSG_LEN];
int i;
taskDelay(sysClkRateGet());
for (i = 0; i < NUM_MSGS; i++) {
taskDelay(0);
sprintf(buf, "Send2 %d", i);
if (msgQSend(msgQId, buf, strlen(buf) + 1, WAIT_FOREVER, MSG_PRI_NORMAL) == ERROR) {
printf("Send 2 msgQSend failed!\n");
return;
}
if (i == 5) {
sprintf(buf, "Send2 URG %d", i);
if (msgQSend(msgQId, buf, strlen(buf) + 1, WAIT_FOREVER, MSG_PRI_URGENT) == ERROR) {
printf("Send 2 msgQSend failed!\n");
return;
}
}
}
}
void receiveTask1(void)
{
char buf[MAX_MSG_LEN];
int i;
for (i = 0; i < NUM_MSGS; i++) {
if (msgQReceive(msgQId, buf, MAX_MSG_LEN, WAIT_FOREVER) == ERROR) {
printf("Rx task 1 msgQReceive failed.\n");
} else {
printf("Task 1 received %s\n", buf);
}
}
}
void receiveTask2(void)
{
char buf[MAX_MSG_LEN];
int i;
for (i = 0; i < 10; i++) {
if (msgQReceive(msgQId, buf, MAX_MSG_LEN, WAIT_FOREVER) == ERROR) {
printf("Rx task 2 msgQReceive failed.\n");
} else {
printf("Task 2 received %s\n", buf);
}
}
}
void msgQ_init(void)
{
int pri;
taskPriorityGet(0, &pri);
pri++; /* Priority is less than init’s priority, so init
can run to completion. */
if ((msgQId = msgQCreate(MAX_NUM_MSG, MAX_MSG_LEN, MSG_Q_FIFO)) == NULL) {
printf("msgQCreate failed!\n");
return;
}
if (taskSpawn("task1Tx", pri, 0, 1000, (FUNCPTR) sendTask1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0) == ERROR) {
printf("taskSpawn Tx1 failed!\n");
}
if (taskSpawn("task2Tx", pri, 0, 1000, (FUNCPTR) sendTask2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0) == ERROR) {
printf("taskSpawn Tx 2 failed!\n");
}
if (taskSpawn("task1Rx", pri, 0, 1000, (FUNCPTR) receiveTask1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0) == ERROR) {
printf("taskSpawn Rx 1 failed!\n");
}
if (taskSpawn("task2Rx", pri, 0, 1000, (FUNCPTR) receiveTask2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0) == ERROR) {
printf("taskSpawn Rx 2 failed!\n");
}
}
2.4.2 QNX Neutrino 版本(信息队列)
要在 QNX Neutrino 中实现同样的功能,我们有两种不同的选择方案。我们可以将VxWorks 中的原始任务映射成相同进程内的线程,或使其成为不同的进程。这里对两种方案都作了介绍。
以下是同一进程内的线程方案:
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#include "sys/QNX Neutrino.h"
#include "sys/types.h"
#include "pthread.h"
#include "mqueue.h"
#include "sched.h"
#define MAX_NUM_MSG 5
#define MAX_MSG_LEN 100
#define NUM_MSGS 2*MAX_NUM_MSG
#define MSG_PRI_NORMAL 10
#define MSG_PRI_URGENT 20
#define MQ_NAME "simple_queue"
mqd_t msgQId;
void *sendTask1(void *arg)
{
static char buf[MAX_MSG_LEN];
int i;
for (i = 0; i < NUM_MSGS; i++) {
/* Yield to allow other tasks to run. Otherwise FIFO means that
this task will run until blocked. */
sched_yield();
/* Write and send a message. */
sprintf(buf, "Send1 %d", i);
if (mq_send(msgQId, buf, strlen(buf) + 1, MSG_PRI_NORMAL) < 0) {
printf("Send 1 msgQSend failed!\n");
return (NULL);
}
if (i == 3) {
/* Send an urgent message. */
sprintf(buf, "Send1 URG %d", i);
if (mq_send(msgQId, buf, strlen(buf) + 1, MSG_PRI_URGENT) < 0) {
printf("Send 1 msgQSend failed!\n");
return (NULL);
}
}
}
return (NULL);
}
void *sendTask2(void *arg)
{
static char buf[MAX_MSG_LEN];
int i;
for (i = 0; i < NUM_MSGS; i++) {
sched_yield();
sprintf(buf, "Send2 %d", i);
if (mq_send(msgQId, buf, strlen(buf) + 1, MSG_PRI_NORMAL) < 0) {
printf("Send 2 msgQSend failed!\n");
return (NULL);
}
if (i == 5) {
sprintf(buf, "Send2 URG %d", i);
if (mq_send(msgQId, buf, strlen(buf) + 1, MSG_PRI_URGENT) < 0) {
printf("Send 2 msgQSend failed!\n");
return (NULL);
}
}
}
return (NULL);
}
void *receiveTask1(void *arg)
{
char buf[MAX_MSG_LEN];
int i;
unsigned prio;
for (i = 0; i < NUM_MSGS; i++) {
if (mq_receive(msgQId, buf, MAX_MSG_LEN, &prio) < 0) {
printf("Rx task 1 msgQReceive failed.\n");
} else {
printf("Task 1 received %s\n", buf);
}
}
return (NULL);
}
void *receiveTask2(void *arg)
{
char buf[MAX_MSG_LEN];
int i;
unsigned prio;
for (i = 0; i < 10; i++) {
if (mq_receive(msgQId, buf, MAX_MSG_LEN, &prio) < 0) {
printf("Rx task 2 msgQReceive failed.\n");
} else {
printf("Task 2 received %s\n", buf);
}
}
return (NULL);
}
void msgQ_init(void)
{
int pri;
pthread_t tid[4];
pthread_attr_t attrib;
struct sched_param param;
struct sched_param our_param;
int i;
struct mq_attr mqattr;
pthread_attr_init(&attrib);
pthread_attr_setinheritsched(&attrib, PTHREAD_EXPLICIT_SCHED);
pthread_attr_setschedpolicy(&attrib, SCHED_FIFO);
sched_getparam(0, &our_param);
param.sched_priority = our_param.sched_priority - 1;
pthread_attr_setschedparam(&attrib, ¶m);
memset(&mqattr, 0, sizeof(mqattr));
mqattr.mq_maxmsg = MAX_NUM_MSG;
mqattr.mq_msgsize = MAX_MSG_LEN;
mq_unlink(MQ_NAME);
if ((msgQId = mq_open(MQ_NAME, O_RDWR | O_CREAT, S_IRUSR | S_IWUSR, &mqattr)) < 0) {
printf("msgQCreate failed!\n");
return;
}
if (pthread_create(&tid[0], &attrib, sendTask1, NULL) < 0) {
printf("taskSpawn Tx1 failed!\n");
}
if (pthread_create(&tid[1], &attrib, sendTask2, NULL) < 0) {
printf("taskSpawn Tx2 failed!\n");
}
if (pthread_create(&tid[2], &attrib, receiveTask1, NULL) < 0) {
printf("taskSpawn Rx1 failed!\n");
}
if (pthread_create(&tid[3], &attrib, receiveTask2, NULL) < 0) {
printf("taskSpawn Rx2 failed!\n");
}
for (i = 0; i < 3; i++)
pthread_join(tid[0], NULL);
mq_unlink(MQ_NAME);
return;
}
int main(int argc, char *argv[])
{
msgQ_init();
return;
}
2.4.3 使用单独进程的 QNX Neutrino 版本
以下是使用相同代码的版本,但此时采用了单独进程:
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#include "sys/QNX Neutrino.h"
#include "sys/types.h"
#include "pthread.h"
#include "mqueue.h"
#include "sched.h"
#include "unistd.h"
#include "spawn.h"
#include "fcntl.h"
#include "sys/wait.h"
#define MAX_NUM_MSG 5
#define MAX_MSG_LEN 100
#define NUM_MSGS 2*MAX_NUM_MSG
#define MSG_PRI_NORMAL 10
#define MSG_PRI_URGENT 20
#define MQ_NAME "simple_queue"
mqd_t msgQId;
void sendTask1(void)
{
static char buf[MAX_MSG_LEN];
int i;
for (i = 0; i < NUM_MSGS; i++) {
/* Yield to allow other tasks to run. Otherwise FIFO means that
this task will run until blocked. */
sched_yield();
/* Write and send a message. */
sprintf(buf, "Send1 %d", i);
if (mq_send(msgQId, buf, strlen(buf) + 1, MSG_PRI_NORMAL) < 0) {
printf("Send 1 msgQSend failed!\n");
return;
}
if (i == 3) {
/* Send an urgent message. */
sprintf(buf, "Send1 URG %d", i);
if (mq_send(msgQId, buf, strlen(buf) + 1, MSG_PRI_URGENT) < 0) {
printf("Send 1 msgQSend failed!\n");
return;
}
}
}
return;
}
void sendTask2(void)
{
static char buf[MAX_MSG_LEN];
int i;
for (i = 0; i < NUM_MSGS; i++) {
sched_yield();
sprintf(buf, "Send2 %d", i);
if (mq_send(msgQId, buf, strlen(buf) + 1, MSG_PRI_NORMAL) < 0) {
printf("Send 2 msgQSend failed!\n");
return;
}
if (i == 5) {
sprintf(buf, "Send2 URG %d", i);
if (mq_send(msgQId, buf, strlen(buf) + 1, MSG_PRI_URGENT) < 0) {
printf("Send 2 msgQSend failed!\n");
return;
}
}
}
return;
}
void receiveTask1(void)
{
char buf[MAX_MSG_LEN];
int i;
unsigned prio;
for (i = 0; i < NUM_MSGS; i++) {
if (mq_receive(msgQId, buf, MAX_MSG_LEN, &prio) < 0) {
printf("Rx task 1 msgQReceive failed.\n");
} else {
printf("Task 1 received %s\n", buf);
}
}
return;
}
void receiveTask2(void)
{
char buf[MAX_MSG_LEN];
int i;
unsigned prio;
for (i = 0; i < 10; i++) {
if (mq_receive(msgQId, buf, MAX_MSG_LEN, &prio) < 0) {
printf("Rx task 2 msgQReceive failed.\n");
} else {
printf("Task 2 received %s\n", buf);
}
}
return;
}
void msgQ_init(int first)
{
int i;
if (first) {
struct mq_attr mqattr;
memset(&mqattr, 0, sizeof(mqattr));
mqattr.mq_maxmsg = MAX_NUM_MSG;
mqattr.mq_msgsize = MAX_MSG_LEN;
mq_unlink(MQ_NAME);
if ((msgQId = mq_open(MQ_NAME, O_RDWR | O_CREAT, S_IRUSR | S_IWUSR, &mqattr)) < 0) {
printf("msgQCreate failed!\n");
return;
}
} else {
if ((msgQId = mq_open(MQ_NAME, O_RDWR)) < 0) {
printf("msgQOpen failed!\n");
return;
}
}
return;
}
int main(int argc, char *argv[])
{
if (argc == 1) {
pid_t pid[3];
char buf[10];
int i;
msgQ_init(1);
for (i = 0; i < 3; i++) {
sprintf(buf, "%d", i + 2);
argv[1] = buf;
argv[2] = NULL;
pid[i] = spawnv(P_NOWAIT, argv[0], argv);
}
sendTask1();
for (i = 0; i < 3; i++)
waitpid(pid[i], NULL, WEXITED);
mq_unlink(MQ_NAME);
} else {
int num;
num = atoi(argv[1]);
msgQ_init(0);
switch (num) {
case 2:
sendTask2();
break;
case 3:
receiveTask1();
break;
case 4:
receiveTask2();
break;
default:
break;
}
}
return;
}
共享内存
共享内存可用于数据的简单共享。由于所有任务都共享同一地址空间,因此共享数据结构是毫不费力的。任务能建立数据结构,并使用指针通过在不同上下文中运行的代码直接参考数据。
QNX Neutrino 通过标准 POSIX shm_* 调用提供对共享内存的访问,这样能使不同进程(不共享同一地址空间)中的线程互相通信。与在 VxWorks中一样,同一进程中的线程能声明全局数据结构(可使用在不同上下文中运行的直接代码指针法访问)。这需要使用适当的同步原语保护对共享数据的同时访问。
要注意确保在线程之间传递正确的地址信息。在 QNX Neutrino 中使用的虚拟内存会产生不同的起始地址的共享内存块,因此,应计算与分配的共享内存块(而非绝对地址)起始有关的所有指针。
进程内的多个线程可共享该进程的内存。要确保在进程间共享内存,您必须首先建立一个共享内存区,然后将该内存区映射到进程的地址空间。函数 shm_open() 具有与 open() 相同的参数,然后它会将文件描述符退回对象。与常规文件一样,该功能允许用户建立新的共享内存对象或打开已有的共享内存对象。
当建立一个新的共享内存对象时,对象大小会设置为零。要设置大小,您可使用 ftruncate() 或 shm_ctl() 函数。请注意,ftruncate() 与设置文件大小的函数完全相同。
当取得用于内存对象的文件描述符后,您可使用函数 mmap() 将对象(或其一部分)映射到进程的地址空间内。函数 mmap() 是 QNX Neutrino 中内存管理的基础,因此需要详细介绍其功能。函数 mmap() 是按下列方式定义的:
void *mmap(void *where_i_want_it, size_t length,
int memory_protections, int mapping_flags, int fd, off_t offset_within_shared_memory);
简单来说,其含义是:“共享内存长度字节的映射(位于共享内存对象中的 offset_within_shared_memory)与 fd 有关。”
图8:QNX Neutrino 中的函数 mmap()。
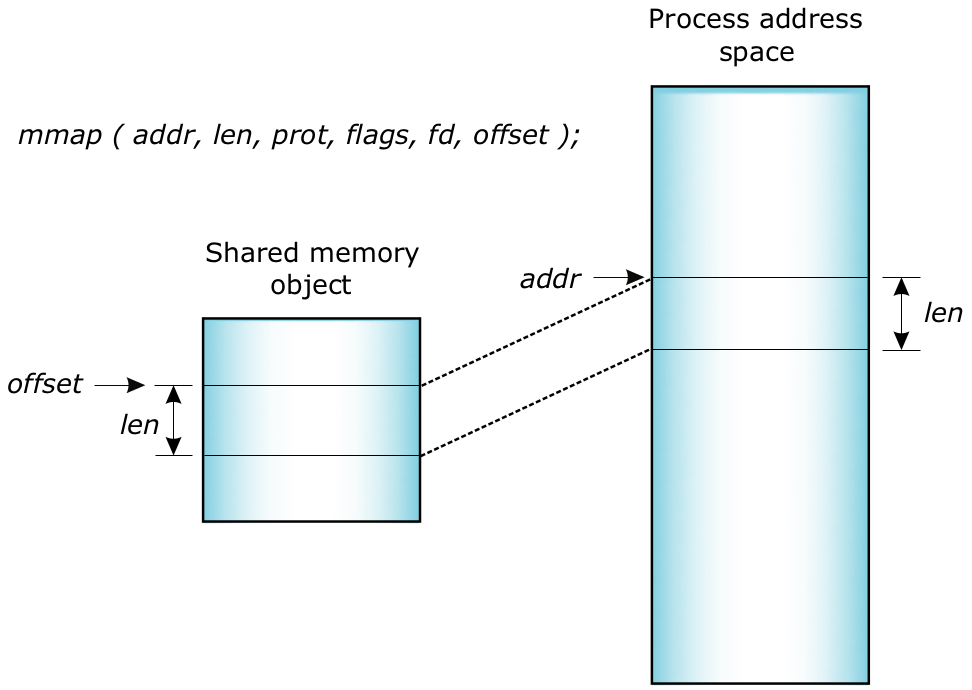
您可以使用 munmap() 从地址空间取消全部或部分共享内存对象的映射。该基元不仅限于取消共享内存的映射,它还可用于取消进程内任何内存区的映射。当与针对 mmap() 的 MAP_ANON 标志连用时,用户能轻松实现专用的页级分配器/释放器。您能使用 mprotect() 更改对内存映射区的保护。与函数 munmap() 一样, mprotect() 不仅限于共享内存区,它能更改对进程内的任何内存区的保护。
2.4.4 VxWorks 共享内存实例
在该实例中,两个任务彼此之间声明了一些共享数据区,并使用信号量对针对该区域的访问进行同步。信号量可防止对该区域的同时访问。
#include "stdio.h"
#include "sysLib.h"
#include "string.h"
#include "taskLib.h"
SEM_ID mSem;
struct {
char writeArea[128];
} shareThis;
void shared1(void)
{
int i;
for (i = 0; i < 10; i++) {
/* Shared area is mutex-protected. */
semTake(mSem, WAIT_FOREVER);
/* Delay for 2 seconds */
taskDelay(sysClkRateGet() * 2);
/* Print and then change the shared memory. */
printf(shareThis.writeArea);
sprintf(shareThis.writeArea, "This is shared1 (%d).\n", i);
/* Release the mutex. */
semGive(mSem);
}
}
void shared2(void)
{
int i;
/* Delay for one second to let the shared1 task grab
the mutex. */
taskDelay(sysClkRateGet());
for (i = 0; i < 10; i++) {
/* Shared area is mutex-protected. */
semTake(mSem, WAIT_FOREVER);
printf("Shared 2 reads %s", shareThis.writeArea);
semGive(mSem);
}
}
void share_init(void)
{
int pri;
/* Priority less than init’s priority, so tasks start and wait
for init to complete. */
taskPriorityGet(0, &pri);
pri++;
mSem = semMCreate(SEM_Q_PRIORITY);
if (mSem == NULL) {
printf("semMCreate failed\n");
return;
}
strcpy(shareThis.writeArea, "Initial starting string\n");
if (taskSpawn("Shared1", pri, 0, 1000, (FUNCPTR) shared1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0) == ERROR) {
printf("taskSpawn 1 failed!\n");
}
if (taskSpawn("Shared2", pri, 0, 1000, (FUNCPTR) shared2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0) == ERROR) {
printf("taskSpawn 2 failed!\n");
}
}
2.4.5 QNX Neutrino 版本(共享内存)
在 QNX Neutrino 中,我们也有两种方案可实现同样的功能。在以下的单线程实例中,同一进程内的线程会自动共享内存。为防止对共享区的同时访问,我们需要一种互斥机制。这是通过使用互斥锁实现的。
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#include "sys/types.h"
#include "sys/QNX Neutrino.h"
#include "pthread.h"
#include "unistd.h"
pthread_mutex_t *mmutex;
struct {
char writeArea[128];
} shareThis;
void *shared1(void *arg)
{
int i;
for (i = 0; i < 10; i++) {
/* Shared area is mutex-protected. */
pthread_mutex_lock(mmutex);
/* Print and then change the shared memory. */
printf(shareThis.writeArea);
sprintf(shareThis.writeArea, "Thread 1 Writes: This is shared 1
(%d).\n", i);
/* Release mutex. */
pthread_mutex_unlock(mmutex);
/* Delay for 2 seconds */
delay(2000);
}
return (NULL);
}
void *shared2(void *arg)
{
int i;
/* Delay for one second to let the shared1 task grab
the mutex. */
delay(1000);
for (i = 0; i < 10; i++) {
/* Shared area is mutex-protected. */
pthread_mutex_lock(mmutex);
printf("Thread 2 reads: %s", shareThis.writeArea);
pthread_mutex_unlock(mmutex);
/* Delay for 1 seconds */
delay(1000);
}
return (NULL);
}
void share_init(void)
{
int pri;
pthread_t tid[2];
pthread_attr_t attrib;
struct sched_param param;
struct sched_param our_param;
int i;
pthread_attr_init(&attrib);
pthread_attr_setinheritsched(&attrib, PTHREAD_EXPLICIT_SCHED);
pthread_attr_setschedpolicy(&attrib, SCHED_RR);
sched_getparam(0, &our_param);
param.sched_priority = our_param.sched_priority - 1;
pthread_attr_setschedparam(&attrib, ¶m);
mmutex = malloc(sizeof(pthread_mutex_t));
pthread_mutex_init(mmutex, NULL);
strcpy(shareThis.writeArea, "Initial starting string\n");
if (pthread_create(&tid[0], &attrib, shared1, NULL) < 0) {
printf("taskSpawn 1 failed!\n");
}
if (pthread_create(&tid[1], &attrib, shared2, NULL) < 0) {
printf("taskSpawn 2 failed!\n");
}
for (i = 0; i < 2; i++) {
pthread_join(tid[i], NULL);
}
return;
}
int main(int argc, char *argv[])
{
share_init();
return (0);
}
2.4.6 使用单独进程的 QNX Neutrino 版本
在使用多线程时,需要明确定义共享内存。在该实例中,两个进程映射到适当的共享内存区,因此两个进程都能访问该内存区。定义一个互斥体并将其置入共享内存,然后使用它对两个进程进行同步。
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#include "sys/types.h"
#include "sys/QNX Neutrino.h"
#include "pthread.h"
#include "unistd.h"
#include "spawn.h"
#include "fcntl.h"
#include "sys/wait.h"
#include "sys/mman.h"
#define roundup(x, y) ((((x)+((y)-1))/(y))*(y))
#define SHAREDNAME "/shared_test"
struct sharedarea {
pthread_mutex_t mmutex;
char writeArea[128];
};
struct sharedarea *sharedThis;
void shared1(void)
{
int i;
for (i = 0; i < 10; i++) {
/* Shared area is mutex-protected. */
pthread_mutex_lock(&(sharedThis->mmutex));
/* Print the shared memory before changing it. */
printf("%s", sharedThis->writeArea);
sprintf(sharedThis->writeArea, "Proc 1 Writes: This is shared 1 (%d).\n", i);
/* Release the mutex. */
pthread_mutex_unlock(&(sharedThis->mmutex));
/* Delay for 2 seconds */
delay(2000);
}
return;
}
void shared2(void)
{
int i;
/* Delay for one second to let the shared1 task grab the mutex. */
delay(1000);
for (i = 0; i < 10; i++) {
/* Shared area is mutex-protected. */
pthread_mutex_lock(&(sharedThis->mmutex));
printf("Proc 2 reads: %s", sharedThis->writeArea);
pthread_mutex_unlock(&(sharedThis->mmutex));
/* Delay for 1 seconds */
delay(1000);
}
return;
}
void share_init(int first)
{
int size;
int fd;
void *addr;
if (first) {
shm_unlink(SHAREDNAME);
fd = shm_open(SHAREDNAME, O_CREAT | O_RDWR, S_IRUSR | S_IWUSR);
} else {
fd = shm_open(SHAREDNAME, O_RDWR, 0);
}
size = sizeof(*sharedThis);
size = roundup(size, 4096); // round to page size
addr = (void *)mmap(0, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, (long)0);
close(fd);
sharedThis = (struct sharedarea *)addr;
return;
}
int main(int argc, char *argv[])
{
pid_t pid;
pthread_mutexattr_t attr;
if (argc == 1) {
shm_unlink(SHAREDNAME);
share_init(1);
pthread_mutexattr_init(&attr);
pthread_mutexattr_setpshared(&attr, PTHREAD_PROCESS_SHARED);
pthread_mutex_init(&(sharedThis->mmutex), &attr);
strcpy(sharedThis->writeArea, "Initial starting string\n");
argv[1] = "1";
argv[2] = NULL;
pid = spawnv(P_NOWAIT, argv[0], argv);
shared1();
waitpid(pid, NULL, WEXITED);
shm_unlink(SHAREDNAME);
} else {
share_init(0);
shared2();
}
return (0);
}
套接字与远程过程调用 (RPC)
套接字提供了任务间双向通信的手段,而且都是以本机和通过网络的方式进行的。在建立套接字时,您还要指定协议(UDP 或 TCP)。TCP 套接字为套接字的两端之间提供了可靠的双向通信。VxWorks 套接字与 BSD套接字接口实现代码兼容。QNX Neutrino 提供的套接字接口也是基于BSD 模式的。两种操作系统都提供了远程过程调用 (RPC) 工具。
信号
信号是一种可用于任务间通信的软件信令机制。信号会以异步方式发送以执行接收的任务。任务能使信号处理程序与具体信号产生关联;只要发送了适当的信号,就会调用这些处理程序。VxWorks 支持 POSIX 1003.1 信号接口和 BSD 信号接口。QNX Neutrino 还同时提供了 POSIX 信号工具和基于语义的 BSD 信号工具。
监视程序计时器
VxWorks 的监视程序计时器允许任务在规定的延迟期内,根据计时器的截止时限执行功能。任务会建立一个计时器,然后通过使计时器与延迟产生关联,并利用针对延迟截止时间的函数调用启动计时器。
如果计时器在延迟期结束前被取消,计时器就不会触发。请注意,传递至监视程序计时器的函数是在系统时钟的中断服务例程 (ISR) 的上下文中执行的。这就限制了在回调例程中可实现的功能。用户还能使用 POSIX 1003.1b 时钟和计时器接口。
QNX Neutrino 启用了 POSIX 1003.1b 时钟和计时器接口,从而允许线程将来在特定时间内自行发送信号。QNX Neutrino 提供了功能全面的事件发送机制,它能用于接收系统事件(包括计时器到期)通知。
2.4.7 VxWorks 监视程序计时器的实例
在该实例中,建立了一个计时器。当计时器触发时,监视程序例程会使用信号量向任务发送信号。等待该信号的任务会继续进行,并执行要求的处理,然后会重置计时器。
#include "stdio.h"
#include "sysLib.h"
#include "string.h"
#include "taskLib.h"
#include "semLib.h"
#include "wdLib.h"
#include "logLib.h"
WDOG_ID wDog;
SEM_ID bSem;
void wDogRoutine(void)
{
logMsg("\nwDog fired!\n", 0, 0, 0, 0, 0, 0);
semGive(bSem);
}
void watchDogTask(void)
{
int i;
for (i = 0; i < 10; i++) {
/* Wait for signal from wdog to go ahead. */
semTake(bSem, WAIT_FOREVER);
printf("Task received watch dog sem.\n");
/* Fire off the watch dog again in one second. */
if (wdStart(wDog, sysClkRateGet(), (FUNCPTR) wDogRoutine, 0) == ERROR) {
printf("wdStart failed in task!\n");
}
}
}
void watchDog_init(void)
{
bSem = semBCreate(SEM_Q_PRIORITY, SEM_EMPTY);
if (bSem == NULL) {
printf("semBCreate failed\n");
return;
}
wDog = wdCreate();
if (wDog == NULL) {
printf("wdCreate failed \n");
return;
}
/* Fire off the watch dog in one second. */
if (taskSpawn("watchDog", 100, 0, 1000, (FUNCPTR) watchDogTask, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0) == ERROR) {
printf("watchDog task spawn failed!\n");
}
if (wdStart(wDog, sysClkRateGet(), (FUNCPTR) wDogRoutine, 0) == ERROR) {
printf("wdStart failed!\n");
}
}
2.4.8 QNX Neutrino 版本(监视程序计时器)
在 QNX Neutrino 中,计时器的使用方式也完全相同。建立一个线程,然后专门用于在计时器触发时,接收内核发出的脉冲。当计时器触发时,监视程序例程会通过条件变量上的信令向等待的线程发送信号。执行完需要的处理后,线程会重置计时器。
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#include "sys/types.h"
#include "sys/QNX Neutrino.h"
#include "pthread.h"
pthread_mutex_t wd_mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t wd_cond = PTHREAD_COND_INITIALIZER;
struct sigevent event;
int timer_chid;
timer_t timer_id;
struct itimerspec itime;
#define TIMER_PULSE_CODE _PULSE_CODE_MINAVAIL
void *wDogRoutine(void *arg)
{
int rcvid;
struct _pulse msg;
while (1) {
rcvid = MsgReceive(timer_chid, &msg, sizeof(msg), NULL);
if (rcvid == 0) { /* we got a pulse */
if (msg.code == TIMER_PULSE_CODE) {
printf("\nwDog fired!\n");
pthread_cond_signal(&wd_cond);
}
}
}
return (NULL);
}
void *watchDogTask(void *arg)
{
int i;
for (i = 0; i < 10; i++) {
/* Wait for a signal from wdog to go ahead. */
pthread_mutex_lock(&wd_mutex);
pthread_cond_wait(&wd_cond, &wd_mutex);
pthread_mutex_unlock(&wd_mutex);
printf("Task received watch dog sem: %d.\n", i);
itime.it_value.tv_sec = 1;
itime.it_value.tv_nsec = 0;
timer_settime(timer_id, 0, &itime, NULL);
}
return (NULL);
}
void watchDog_init(void)
{
pthread_t tid[2];
pthread_attr_t attrib;
struct sched_param param;
struct sched_param our_param;
int i;
setbuf(stdout, NULL);
timer_chid = ChannelCreate(0);
event.sigev_notify = SIGEV_PULSE;
event.sigev_coid = ConnectAttach(0, 0, timer_chid, _NTO_SIDE_CHANNEL, 0);
event.sigev_priority = getprio(0);
event.sigev_code = TIMER_PULSE_CODE;
timer_create(CLOCK_REALTIME, &event, &timer_id);
itime.it_value.tv_sec = 1;
itime.it_value.tv_nsec = 0;
timer_settime(timer_id, 0, &itime, NULL);
pthread_attr_init(&attrib);
pthread_attr_setinheritsched(&attrib, PTHREAD_EXPLICIT_SCHED);
pthread_attr_setschedpolicy(&attrib, SCHED_RR);
sched_getparam(0, &our_param);
param.sched_priority = our_param.sched_priority;
pthread_attr_setschedparam(&attrib, ¶m);
if (pthread_create(&tid[0], &attrib, wDogRoutine, NULL) < 0) {
printf("watchDog routine spawn failed!\n");
}
if (pthread_create(&tid[1], &attrib, watchDogTask, NULL) < 0) {
printf("watchDog task spawn failed!\n");
}
pthread_join(tid[1], NULL);
return;
}
int main(int argc, char *argv[])
{
watchDog_init();
}
2.5 异常处理
2.5.1 VxWorks
VxWorks 中的硬件异常是通过 excLib 库函数处理的。在系统启动过程中,使用与 CPU 架构有关的库调用对异常中断向量表进行初始化。内核启动后,函数 excInit() 会负责建立操作系统工具以处理异常情况,包括衍生 excTask()、任务级异常处理程序。
当任务导致出现异常时,默认的异常处理程序会将与异常和任务有关的信息转存至输出控制台,然后会暂停有问题的任务,以便检查并稍后进行调试。此时可以从异常状态中恢复,也可能不行(通常不行)。可使用函数 excHookAdd() 增加用户异常代码,以增加默认动作。该代码是在正常异常处理结束时调用的。
还可使用信号库 sigLib (一种与 Unix 兼容的接口)处理硬件异常,在这种情况下,使用了 sigvec() 对单独的异常向量进行初始化。这种信号库同时提供了BSD 4.3 与 POSIX 接口,但是这两种应用程序接口 (API) 不能混插。信号确保任务能检测并处理异常。
2.5.2 QNX Neutrino
针对异常处理和异常恢复,QNX Neutrino 提供了多种不同的机制。例如,假设某个设备驱动程序因尝试在分配给另一个进程的内存中写入数据而崩溃。内存管理单元 (MMU) 会通知微内核,微内核会命令生成转储文件以进行事后分析。通过查看该转储文件,您能立即确定哪个代码行是罪魁祸首,然后在现场的所有其他设备遇到同样的漏洞前,为它们准备可下载的修复程序。
当进程终止时,内核会自动收回与该进程有关的所有系统资源。这不仅使应用程序的资源管理变得更简单、更可靠,而且还最大限度减少了由不可用的资源(因缺少自动回收)产生的内存碎片。
就异常处理而言,基于传统宏内核操作系统的许多系统都不具备自动故障检测功能。相反,它们依赖人工处理方法,即由监视系统正常运行的操作员负责。如果系统状态出现异常,操作员会采取适当措施,通常包括系统完全重设。
如果所有任务(包括关键的系统级服务)都共享完全相同的地址空间,单个任务的完整性会使整个系统的完整性面临危险。如果单独的组件(如设备驱动程序)出现故障,整个实时操作系统就会瘫痪!从高可用性 (HA) 角度看,每个软件组件都会成为一个单点故障 (SPOF)。此时真正需要的是一种更具模块化的解决方法。
系统进程间完全支持内存管理单元 (MMU) 的内存保护功能可轻松隔离并保护单独进程。QNX Neutrino 的进程模型还具备动态创建和析构功能,这对高可用性系统尤为重要,因为用户能在现场随时进行故障检测、恢复和在线升级。此外,进程模型还便于您监视外部任务,这有助于检测和诊断故障。
2.5.3 结论
- 两种操作系统中都有用于异常处理的类似的应用程序接口 (API)。移植工作的难度取决于 VxWorks 应用程序中使用了何种异常库。
- QNX Neutrino 具有默认的异常处理程序,它本质上是基于线程/进程的,而不是基于系统的。
- 在 QNX Neutrino 中,可通过重启进程为显示应用程序出现严重故障的信号寻址,同时系统会自动收回应用程序的资源。这是使用 VxWorks 应用程序(常常需要进行系统完全重设)通常无法实现的。在为任何负责“系统正常运行审核”的应用程序确定要求和恢复策略时,都应该重视这种功能。
3 移植元素
如第 1 节中所述,代码移植的简易性与要移植的代码和硬件的关联程度密切相关。例如,由于操作系统的设计理念在本质上有很大区别,因此可能需要对设备驱动程序重新进行深入开发,而对高级应用程序而言,可能只需要使用简单的“重新编译、链接并运行”方法就可完成移植。
通常,进行移植时首先要在硬件平台上建立操作系统(本质上即板级支持包 [BSP] 部分),接下来要启用适当的设备驱动程序,然后将它们集成到操作系统中,最后是移植全部更高层的应用程序。请注意,各种 QNX Neutrino板级支持包中已提供了许多设备驱动程序。
在本节中,我们将为您详细介绍开发生命周期内的这些元素,并就有关的移植工作进行总结。
3.1 启动代码
3.1.1 VxWorks 启动
VxWorks 针对嵌入式应用的基本启动顺序是先执行重设的汇编代码,这可通过 _romInit 代码或 BIOS 完成,具体取决于使用的硬件。该代码可执行建立 CPU 和内存所需的最基本功能,以便将 VxWorks 应用程序加载到随机存储器 (RAM) 中。
图9:VxWorks 的启动顺序。
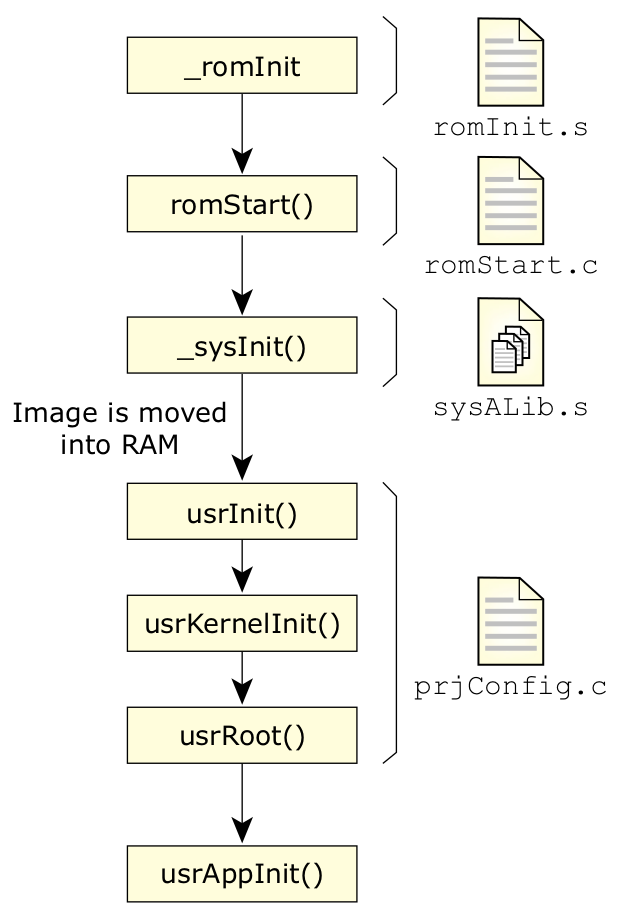
执行完重设代码后,会运行映像加载程序 (_romStart()) (位于 romStart.c 内)。该代码负责将永久存储器(如闪存)内的操作系统/应用程序映像移动到随机存储器 (RAM) 中,而且通常还要进行解压缩和复制。必要时,可在此时将操作系统和应用程序使用的数据内存设为零。
当映像进入随机存储器 (RAM) 后,会从只读存储器 (ROM) 跳转执行随机存储器 (RAM) 内建立处理器和堆栈帧的少量程序集(_sysInit),以便启动服务等级 (COS) 初始化例程usrInit()。
函数 usrInit() 会处理其余必要的设置,以对内核进行初始化(包括初始化异常向量、缓存库、中断和任何附加的硬件初始化)。然后可使用 kernelInit()呼叫建立内核。内核初始化会导致执行 usrRoot()。
usrRoot() 呼叫 负责建立剩余的内核系统(即信号量、信息队列、任务支持等)的剩余部分,初始化内存池子系统、输入/输出基础结构、网络(如需要)、文件系统和其他支持的硬件,最后它会启动 userAppInit(),其中包含用户提供的用于启动用户应用程序的代码。
需要重视的是,用于系统启动的永久储存图像通常由单独的“可执行文件”组成,其中包含所有用户应用程序和配置的内核。操作系统和支持的基础结构本身是使用宏命令 #define 进行配置的,以在建立阶段确定应包含的内容,或应从最终映像中排除的内容。这些宏命令还可确定 prjConfig.c 内的初始化代码如何运行,以建立相应的基础结构。
3.1.2 QNX Neutrino 启动
从软件的角度,当 QNX Neutrino 启动时会按以下步骤进行:处理器会根据复位向量开始执行。初始程序加载程序 (IPL) 会定位操作系统映像,然后将控制权转移至映像内的启动程序。接着,启动程序会配置系统,然后将控制权转移至 QNX Neutrino 微内核和进程管理器 (procnto)。procnto 模块会载入附加的驱动程序和应用程序。
软件执行的第一步是载入操作系统映像。如上所述,这是由初始程序加载程序 (IPL) 完成的。IPL 的初始任务是对硬件进行最低限度的配置以建立一种运行环境,便于启动程序以及随后的 QNX Neutrino 微内核运行。具体说来,该任务包括至少下列步骤:从复位向量中开始执行、配置内存控制器(包括配置芯片选择与/或 PCI 控制器)、配置时钟,以及建立能使 IPL 库执行操作系统验证和设置(映像下载、扫描、设置与跳转)的堆栈。
图10:QNX Neutrino 的启动顺序。
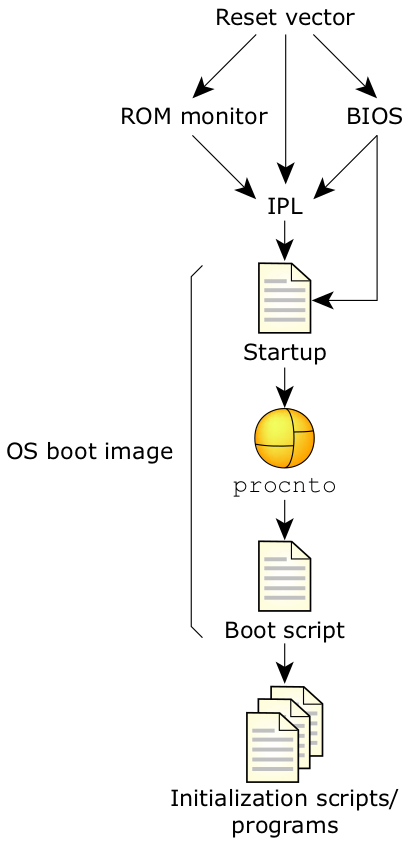
软件执行的第二步是配置处理器和硬件、检测系统资源并启动操作系统。如上所述,这是由启动程序完成的。当初始程序加载程序 (IPL) 在进行必要的最低限度的配置,以使系统进入启动程序可以运行的状态时,启动程序的任务是“完成”配置。如果 IPL 检测到各种资源,它会就该信息与启动程序进行通信(这样它就不必重新检测相同的资源)。为尽量确保 QNX Neutrino 的可配置性,启动程序能对底部计时器、中断控制器、缓存控制器等进行编程。它还具有内核调用功能,即内核可调用代码片断执行与硬件有关的功能。例如,当触发硬件中断时,一些代码段必须确定中断源,另一些代码段必须能清除中断源。注意,启动程序不会配置串行端口的波特率。它也不会初始化标准外围设备(如以太网控制器或 EIDE 硬盘控制器), 这些工作会由稍后启动的驱动程序自行完成。
当完成对系统的初始化并将与系统有关的信息置入系统页区(内核稍后会查看的一段专用内存)后,启动代码会负责将控制权转至 QNX Neutrino 内核与进程管理器 (procnto),由其完成最后的载入步骤。
要建立操作系统,需使用一个单独的映像文件。该映像至少应包含操作系统映像包和支持操作系统的基本功能所需的组件。也可包含应用程序映像,但它们通常储存在单独的文件系统中(如闪存或磁盘),并由映像文件中包含的脚本启动。
实际上,映像文件会组成一个小的文件系统(称为映像文件系统),它具有参考驻留文件(应用程序映像、程序库、操作系统映像、启动脚本等)所需的目录结构。一个名为 mkifs (建立映像文件系统)的程序会使用命令行信息和“生成文件”产生最终映像。
3.1.3 结论
- 您可以重复使用一些复位向量代码,并更改出口点以扩展成启动代码。尽管复位代码的格式有明显区别,但所需的正常功能范围是一样的。
- 需要重新编写剩余的操作系统的建立代码。
- QNX Neutrino 中的启动代码具有与 VxWorks 中的 romStart/usrInit 代码类似的功能。
- QNX Neutrino 的生成文件具有与 VxWorks 中的函数 usrRoot() 类似的功能。
- 无需配置 QNX Neutrino 的内核。内核是作为生成文件可容纳的独立单元提供的。指令缓存与数据缓存都能由内核自动启动,也就是说设备驱动程序需要分配缓存安全的内存。
- QNX Neutrino 中的操作系统与应用程序能以不同格式储存在不同区域(即操作系统本身就是用于启动系统的生成文件的一部分)。除操作系统外,应用程序也可储存在固定文件系统(如磁盘、闪存等)中。这点与 VxWorks 不同,VxWorks 中的应用程序和操作系统必须固定到独立映像中。
3.2 硬件输入/输出设备
两种操作系统都支持各种类型的输入/输出设备(字符设备、块设备、流媒体设备、网络设备等)。还提供了中级基础结构以将硬件组件集成到操作系统中,这样就能使用一致的应用程序接口 (API) 访问硬件。在低层级,可使用设备驱动程序配置、控制和发送/接收来自硬件的数据。在应用层,可使用标准输入/输出命令(开启、读取、写入、关闭等)访问设备。
本节对 QNX Neutrino 和 VxWorks 中的各种硬件集成元素进行了对比介绍。
3.2.1 中断服务例程 (ISR)
3.2.1.1 VxWorks
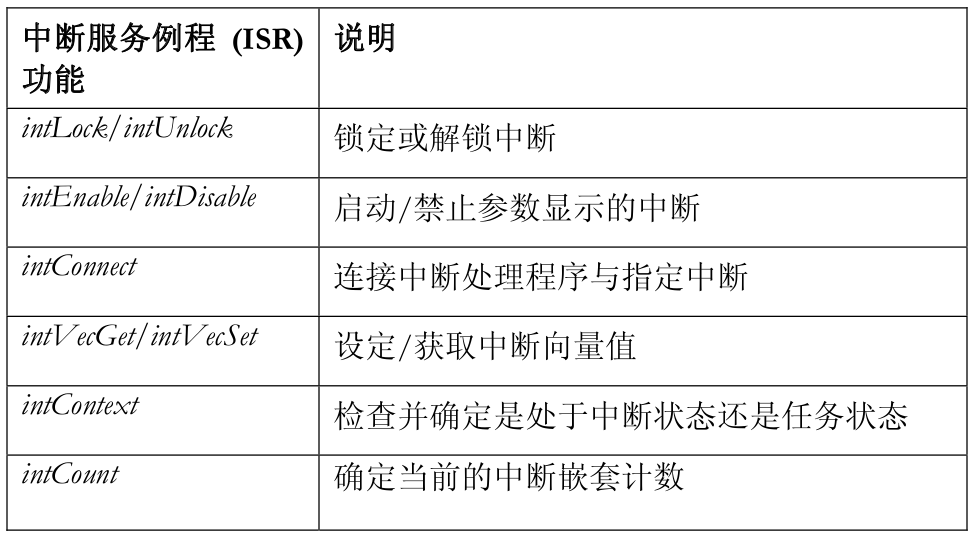
VxWorks 中的中断服务例程是通过 intArchLib(与架构有关的中断例程库)进行处理的。该例程库提供的例程可用于锁定/解锁、启用/禁止中断、为硬件中断 (intConnect()) 添加处理程序,以及处理中断向量表 (intVec*)。还有其他例程可用,这取决于用户使用的 CPU 产品系列。
以下是在 VxWorks 应用程序中使用的主要中断服务例程功能:
以下实例显示了一个中断处理程序,以及它是如何添加到 PowerPC 架构中的:
DRV_CTRL_S drvCtrl;
SEM_ID packetSem;
LOCAL void motFccISR(DRV_CTRL_S * pDrvCtrl)
{
struct fcc_regs *fcc_regs;
unsigned int events;
PQ2IMM *pQ = (PQ2IMM *) vxImmrGet();
fcc_regs = &pQ->fcc_regs[pDrvCtrl->fccNum - 1];
/* Save the event register. */
events = fcc_regs->fcc_fcce;
/* Clear the event that’s causing the interrupt. */
fcc_regs->fcc_fcce = 0xffff0000;
/* Other processing. */
...
/* Signal to task. */
semGive(packetSem);
}
DRV_CTRL_S drvCtrl;
attachInterrupt(void)
{
... taskSpawn("tPacketProcessor", 100, 0, 5000, (FUNCPTR) packetProcessor, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0);
packetSem = semBCreate(SEM_Q_PRIORITY, SEM_EMPTY);
drvCtrl.fccNum = 1;
intConnect(INUM_TO_IVEC(INUM_FCC1), (VOIDFUNCPTR) motFccISR, (int)(&drvCtrl));
...}
packetProcessor(void)
{
while (1) {
semTake(packetSem);
/* Process packet */
...}
}
处理程序是通过使用宏命令,将中断数值映射到中断向量的方式添加到中断的。也可将处理程序的地址和数据值(调用时可用作处理程序的参数)作为参数来传递。
在处理程序内部,可(使用预定义的 PQ2IMM 结构与传递数据结构内包含的信息)直接访问内部内存映射区,确定要访问的适当寄存器以清除中断。还可进行其他处理以应对中断问题。当完成中断处理后,会指定一个信号量以向任务通知出现的中断。
在 VxWorks 中,可从中断服务例程中调用的功能种类受到限制。一般来说,任何可能造成呼叫阻塞的内容都不能使用。这包括 semTake、malloc、printf、等。中断服务例程与任务间的通信(在“中断空间”内)可通过各种方式进行,包括指定信号量或在信息队列上发送信息。
3.2.1.2 QNX Neutrino
在 QNX Neutrino 中,为了安装中断服务例程,软件必须通知操作系统它希望中断服务例程与特定的中断源产生关联。线程会使用 InterruptAttach() 或 InterruptAttachEvent() 函数调用指定它希望哪个中断源与哪个中断服务例程产生关联。当软件希望解除中断服务例程与中断源的关联时,它可以调用
InterruptDetach();
// Example to show attaching an ISR
#define IRQ3 3
extern const sigevent *handle_int3(void *, int);
...
// Obtain I/O Privileges
ThreadCtl(_NTO_TCTL_IO, 0);
// Associate an interrupt handler with IRQ 3
id = InterruptAttach(IRQ3, handle_int3, NULL, 0, 0);
...
// Perform some processing
...
// Done; detach the interrupt source.
InterruptDetach(id);
试图依附中断的线程必须具有输入/输出特权——即有关控制输入/输出端口和影响处理器允许中断标志的特权。只有根账户能获得输入/输出特权,这就有效限制了中断源与中断服务例程代码的关联。
在上述实例中,函数 handle_int3() 是中断服务例程。中断服务例程通常负责确定哪个硬件需要维修、对该硬件进行某种维修(通常对硬件寄存器进行简单的读取与/或写入即可完成)、对中断服务例程与运行在程序内的某些线程之间的共享数据结构进行升级,以及就出现的某种事件向应用程序发送信号。
总之,中断服务例程为处理中断所做的非常少——它只是负责清除中断源,然后安排线程完成处理中断的工作。这是我们建议的方法,原因是多方面的。首先,中断服务例程完成与线程执行之间的上下文切换时间非常短——通常只有几微秒。同时,中断服务例程只能执行有限的功能(包括七种内核功能)。而且,中断服务例程运行的优先级要高于系统内任何软件的 优先级,这就使中断服务例程消耗大量处理器时间,从而会对系统的实时特性产生负面影响。
当中断服务例程处理中断时,除执行七种安全功能以外,它无法进行任何内核调用。这就意味着中断服务例程不应调用任何库函数,因为它们的底层实现能使用内核调用。由于我们的例程库是线程安全型的,因此甚至有些“简单”的库调用都会尝试分配互斥体,(可能)产生内核调用。因为函数 str*() 和 mem*()(如 strcpy() 和 memcpy())在中断服务例程中非常有用,所以会确保这些函数对调用是安全的,并通过显著异常 strdup() 分配内存并使用互斥体。QNX Neutrino 库参考可识别您能从中断服务例程调用的功能。
使用中断时会出现的另外一个问题是,如何对中断服务例程和应用程序的线程之间使用的数据结构进行安全更新。由于中断服务例程运行的优先级高于任何软件线程的优先级,并且由于中断服务例程无法发布内核调用(除注明以外),因此无法使用标准的线程级同步机制(如互斥体、条件变量等)。线程只能保护自己不受中断服务例程导致的抢占的影响。因此,线程会在任何关键数据操作运行周围发出 InterruptDisable() 和 InterruptEnable() 呼叫。由于这些呼叫能有效关闭中断,因此线程应该能使数据操作运行保持绝对最小值。
因为中断服务例程的运行环境非常有限,所以用户通常都希望执行大部分(如非全部)真正的线程级“维修”操作。您可以决定一些需要在中断服务例程中实现的时序要求严格的功能,然后稍后调度线程去做“实际”的工作,或者,您也可以决定无需在中断服务例程中实现任何功能;仅需调度一个线程即可。这是 InterruptAttach() (中断服务例程依附于中断请求[IRQ]) 与 InterruptAttachEvent()(struct sigevent 绑定到中断请求)之间的明显区别。
中断服务例程从硬件中读取一些寄存器后,或者完成进行维修所需的任何处理后,它可能会(也可能不会)调度一个线程去实际完成工作。要调度线程,中断服务例程只需使指针返回 const struct sigevent 结构即可;内核会查看该结构然后将事件发送至目的地。如果中断服务例程决定不调度线程,它仅需返回一个空 (NULL) 值即可。
返回的事件可能是信号或脉冲。您可能发现信号或脉冲令人满意,特别是如果您由于某种原因已经有了信号或脉冲处理程序的话。但请注意,针对中断服务例程我们还能返回 SIGEV_INTR。这是一个特殊事件,它仅用于中断服务例程及其相关的控制线程。从线程级维修中断的一种非常简单、实用和迅速的方法是专门安排一个线程进行中断处理。线程(通过 InterruptAttach())先附加到中断中,然后附加到线程块上,最后等待中断服务例程通知它要完成的工作。阻塞是通过 InterruptWait() 呼叫实现的。该呼叫会保持阻塞,直到中断服务例程返回 SIGEV_INTR 事件。
3.2.1.3 QNX Neutrino 中的中断处理程序实例
#include "errno.h"
#include "fcntl.h"
#include "stdarg.h"
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#include "unistd.h"
#include "sys/iofunc.h"
#include "sys/dispatch.h"
#include "sys/neutrino.h"
#include "sys/resmgr.h"
#include "sys/stat.h"
#include "sys/syspage.h"
#define INTR_THREAD_PRIO 27
void *interrupt_thread(void *data);
struct sigevent intr_event;
int intr_id;
#define NUM_DATA_BYTES 1
unsigned int interrupt_num = 0;
int main(int argc, char **argv)
{
int i;
while ((i = getopt(argc, argv, "i:")) != -1) {
switch (i) {
case 'i':
interrupt_num = atoi(optarg);
break;
default:
printf("Unknown arg \n");
return (EXIT_FAILURE);
break;
}
}
fprintf(stderr, "Using Interrupt %u\n", interrupt_num);
fflush(stdout);
pthread_create(0, NULL, interrupt_thread, NULL);
// Now our main() thread just waits till we get killed
pause();
return EXIT_SUCCESS;
}
const struct sigevent *interrupt_handler(void *event, int id)
{
struct sigevent *return_event = (struct sigevent *)event;
// Uncomment the following lines to pulse every
// NUM_DATA_BYTES'th interrupt. We are pretending we get
// one byte of data per interrupt and only wake up the
// thread after NUM_DATA_BYTES bytes.
// Why do the work of getting the bytes of data from within
// the thread? Because we are pretending that if we don't
// do it at handler time, then we'll miss the data (e.g. no
// buffering on the hardware).
// static unsigned interrupt_counter = 0;
// interrupt_counter++;
// if ( interrupt_counter == NUM_DATA_BYTES ) {
// interrupt_counter = 0;
return return_event;
// } else {
// return NULL;
// }
}
void *interrupt_thread(void *notinuse)
{
unsigned counter = 0;
struct sched_param param;
param.sched_priority = INTR_THREAD_PRIO;
if (sched_setscheduler(0, SCHED_FIFO, ¶m) == -1) {
fprintf(stderr, "Unable to change priority: %s\n", strerror(errno));
exit(EXIT_FAILURE);
}
// We need I/O privileges so we can call InterruptAttach()
if (ThreadCtl(_NTO_TCTL_IO, 0) == -1) {
fprintf(stderr, "Unable to get I/O privileges: %s\n", strerror(errno));
exit(EXIT_FAILURE);
}
// Set up a sigevent that will wake up InterruptWait()
SIGEV_INTR_INIT(&intr_event);
if (interrupt_num == 0) {
// Set interrupt_num to the timer interrupt. On x86,
// this is 0. We do this just to show how to pull info
// from the SYSPAGE.
interrupt_num = SYSPAGE_ENTRY(qtime)->intr;
}
intr_id = InterruptAttach(interrupt_num, interrupt_handler,
&intr_event, sizeof(intr_event), _NTO_INTR_FLAGS_TRK_MSK);
if (intr_id == -1) {
fprintf(stderr, "Unable to attach to irq %u: %s\n", interrupt_num, strerror(errno));
exit(EXIT_FAILURE);
}
for (;;) {
if (InterruptWait(NULL, NULL) == -1) {
fprintf(stderr, "\nInterruptWait interrupted: %s\n", strerror(errno));
} else {
// The interrupt went off, and the interrupt handler
// was called, and the interrupt handler then woke
// us up from InterruptWait() by returning with the
// SIGEV_INTR event.
counter++;
fprintf(stderr, "%u ", counter);
fflush(stderr);
}
}
}
3.2.1.4 结论
- 需就特权与许可权、内存寻址(转换)和内存访问(共享内存映射)正确设置 QNX Neutrino 中断服务例程中的硬件访问,然后才能使用中断服务例程。
- 中断服务例程越短越好。两种操作系统都明确限制了在中断服务例程中能进行的函数调用的类型。QNX Neutrino 进一步限制了在中断服务例程中可使用的操作系统调用。
- 相对而言,将可清除硬件中断根源并执行 semGive(启动一个执行剩余任务级处理的任务)的简单的 VxWorks 中断服务例程转换到 QNX Neutrino 中并不困难。
3.2.2 输入/输出
3.2.2.1 VxWorks
VxWorks 的输入/输出系统在应用层启用了兼容 Unix 和 ANSI-C 的应用程序接口 (API),这就为硬件提供了一致的接口(如图 11 所示)。
图11:VxWorks 的输入/输出系统。
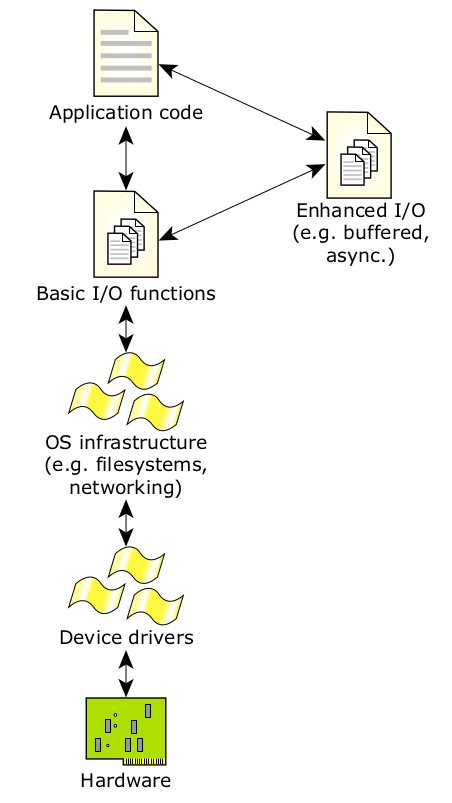
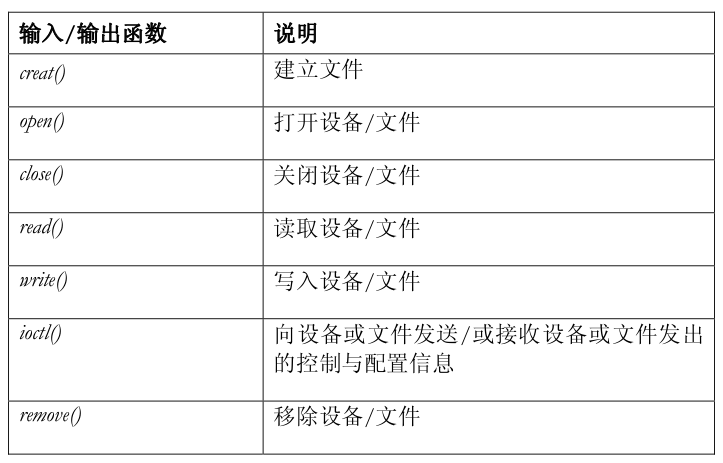
有七个与设备有关的基本输入/输出函数提供了这种功能:
操作系统库中还包括更高级的标准功能(如套接字调用、printf、scanf 等)。
所有这些基本功能都使用“文件描述符”以专门识别有问题的设备或文件。VxWorks 中的文件描述符可在所有任务间共享,而且能从单独的描述符“组合”中分配/返回。在 VxWorks 5.4 系统中可同时使用最多 255 个文件描述符(您可在操作系统启动过程中设置)。
文件描述符可在 open() 或 creat() 调用过程中分配,并通过 close() 解除分配,而且还可在解除分配后重复使用。还使用了分配文件描述符的通用惯例,即将文件描述符 0 分配给标准输入、1 分配给标准输出、2 分配给标准错误。
VxWorks 的设备驱动程序可分为以下几类:
- 基于字符(如 RS-232)
- 块设备访问(如磁盘驱动器)
- 网络
- 异步(使用符合 POSIX 标准的应用程序接口实现)
VxWorks 中的文件系统位于块设备驱动程序的顶部。块设备驱动程序可充当存储媒体(闪存、旋转存储器等)与顶部文件系统之间的媒介。VxWorks支持以下文件系统:

安装文件系统只不过是从适当的程序库中执行函数调用。调用包括文件系统名称、要附加的块设备驱动程序,以及其他与设备有关的文件系统信息。函数调用还可用于按需要对媒体进行格式化和检查。文件系统安装完以后,可通过您熟悉的 stdio 库调用(建立、打开、读取、写入等)读取/写入文件系统。
3.2.2.2 QNX Neutrino
按照 POSIX 和 Unix 中的惯例,这些设备位于/dev 目录下方的操作系统路径名空间内。例如,调制解调器或终端可连接的串行端口可能以下列方式出现在系统中:
/dev/ser1
QNX Neutrino 中的设备驱动程序可分为以下几类:
- 图像——一种特殊文件系统,它能呈现映像中的模块,而且会一直呈现。进程管理器 (procnto) 会自动提供映像文件系统和随机存储器 (RAM) 文件系统。
- 块程序——在块设备上运行的传统文件系统,如硬盘和只读光驱。这包括 Power-Safe、QNX4、DOS、UDF 和 CD-ROM 文件系统。
- 闪存——专门设计满足闪存设备特性要求的非区块导向的文件系统。
- 网络——提供网络文件访问远程主机上的文件系统的文件系统。这包括NFS 和 CIFS (SMB) 文件系统。
- 虚拟程序——为用户提供定制工具的特殊文件系统(如 Inflator 资源管理器)。
在 QNX Neutrino 中,设备驱动程序通常是以资源管理器的形式实现的。资源管理器就是一种用户级程序,它能接收其他程序发出的信息,而且能在必要时与硬件通信。需要通知硬件的资源管理器与客户程序之间的特殊结合,是通过路径名空间映射保持的;需要在路径名与资源管理器之间建立关联。客户程序可继续使用标准 POSIX 机制(open()、 close() 等)以访问资源。由于多数资源管理器收到的许多信息都是用于一个常用函数集的,因此QNX Neutrino 为共享库内的大部分常用函数提供了默认处理程序。这就能确保驱动程序的开发人员无需编写另外的代码,就能处理这些常用函数。程序库自动提供了下列常用函数(除其他函数外):
- open()
- close()
- read()
- write()
- stat()
- unlink()
- fstat()
- devctl()
- lseek()
基于字符的设备驱动程序可作为此类设备的串行端口、并行端口、文本模式控制台、伪终端 (ptys)。
程序可使用标准的 open()、close()、read() 和 write() 应用程序接口函数访问字符设备。还提供了其他函数用于处理字符设备的其他方面,例如波特率、奇偶校验、流量控制等。
由于运行多个字符设备很正常,因此已将这些设备驱动设计成一个驱动程序族,并集中到了一个名为 io-char 的程序库中,以最大限度增加代码重用。
图12:QNX Neutrino 中的设备输入/输出。
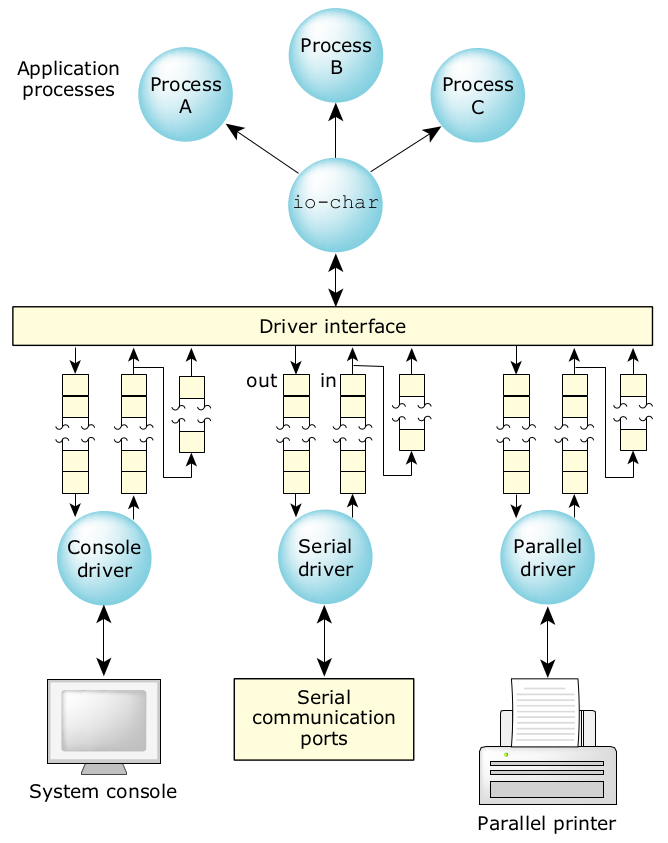
io-char 库模块含有所有支持设备上的 POSIX 语义的代码。它还包含大量可实现字符输入/输出功能的代码,这些功能超越了 POSIX 标准,但正是实时系统所需的。由于该代码位于公用程序库中,因此所有驱动程序都继承了这些功能。驱动程序是调用程序库的执行进程。在运行时,驱动程序首先启动并调用 io-char 管理器。驱动程序本身与 QNX Neutrino 中的其他进程一样,它们可根据被控制硬件的特征和客户请求的服务,以不同的优先级运行。当单独的字符设备运行时,增加另外设备所需的内存成本是最少的,因为只有实现新驱动程序结构的代码是最新的。
QNX Neutrino 提供了种类丰富的文件系统。像操作系统中大部分提供服务的进程一样,这些文件系统可在内核外部运行;应用程序可通过 POSIX 应用程序接口 (API) 的共享库实现产生的信息,以通信方式使用这些文件系统。这些文件系统中的大部分都是资源管理器。每个文件系统都采用一部分路径名空间(即一个装入点)并通过标准 POSIX 应用程序接口(open()、close()、read()、write()、lseek() 等)提供文件系统服务。文件系统的资源管理器 会接管装入点,并管理其下部的目录结构。它们还会检查单独的路径名组件,以获得许可权和访问授权。
这种实现允许文件系统以动态方式启动和关闭;多个文件系统能并行运行,并赋予应用程序独立统一的路径名空间和接口,不必考虑底层文件系统的配置和数量。
图13:QNX Neutrino 中的文件系统分层。
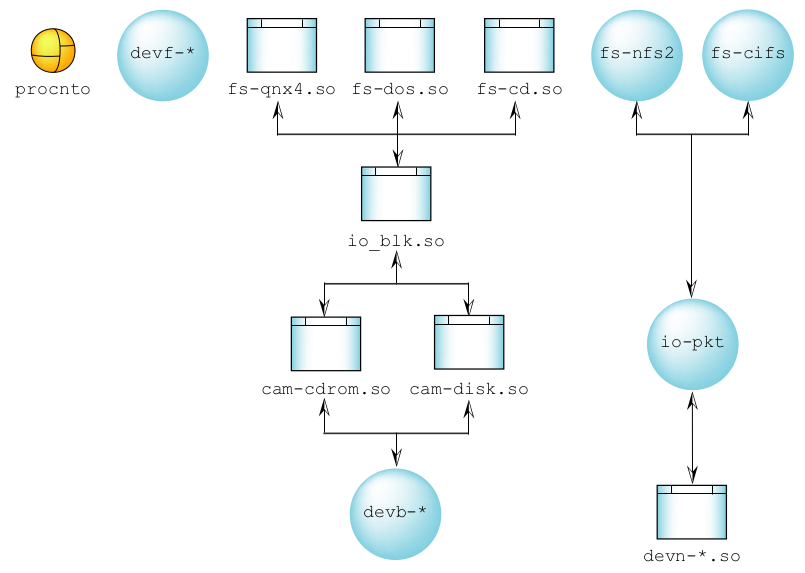
因为在 QNX Neutrino 中运行多个文件系统很正常, 因此已将它们设计成一个驱动程序族和共享库,以最大限度增加代码重用。这意味着增加另外文件系统所需的成本通常会比预期的少得多。当初始文件系统运行时,添加文件系统所增加的内存成本是最少的,因为只有实现新系统协议的代码才会添加到系统中。可稍后以动态方式载入文件系统共享库,以提供文件系统接口和服务。“文件系统”共享库在物理磁盘上的一组区块上实现了文件系统协议或“特征”。由于文件系统无法内建到操作系统内核中,因此它们可作为动态实体,根据需求进行加载或卸载。
大部分文件系统共享库都位于区块输入/输出模块 (io-blk) 的顶部。该模块也可充当资源管理器,并为每个物理设备导出区块专用文件。这些文件代表每个原始磁盘,并能使用所有正常的 POSIX 文件基元(open()、 close()、 read()、write()、lseek() 等)对其进行访问。
3.2.2.3 结论
- VxWorks 与 QNX Neutrino 在应用层都使用了完全相同的兼容 ANSI-C/POSIX 的应用程序接口 (API)。对各种例程(如 ioctl)具体调用的一致支持,取决于对应的设备驱动程序实现的方式。
- QNX Neutrino 与 VxWorks 使用的输入/输出基础结构不同而且不兼容。
- 两种系统在向操作系统安装/集成文件系统或设备驱动程序方面是完全不同的。
- QNX Neutrino 提供了比 VxWorks 更丰富的文件系统选项。
3.2.3 设备驱动程序
设备驱动程序允许操作系统和应用程序以常见方式使用底层硬件(如磁盘驱动器、网络接口)。
3.2.3.1 VxWorks
要实现可直接集成到 VxWorks 操作系统的设备驱动程序,您需要针对有问题的设备实现基本的输入/输出功能(如 3.2.2.1 节所述)。输入/输出功能的底层实现会根据编写的设备驱动程序类型(如终端、网络、磁盘)而变化。输入/输出功能包括对任何支持的输入输出控制 (IOCTL) 命令的适当响应。
设备驱动程序的安装会随设备类型的不同而变化。多数设备都是使用函数iosDrvInstall()/iosDevAdd() 安装的,以进入操作系统的设备驱动程序表中的输入 / 输出功能,并实例化驱动程序。网络设备驱动程序是使用函数muxDevLoad()/muxBind() 安装的。要检查设备驱动程序表,您可使用 iosShow(iosDevShow()/iosDrvShow())或 muxShow 例程。设备处理程序的功能可以下列方式运行:
- 作为单独任务(如闪存文件系统的一部分)
- 在系统任务的上下文中(如用于网络功能的 tNetTask)
- 在用户任务的上下文中(如输入/输出功能)
或者上述三种情况的组合。
当然,也可使用通过某些用户定义的机制与应用程序交互的专用应用程序接口实现设备驱动程序。
在任何 VxWorks 实现中,驱动程序会作为内核和用户应用程序以相同的特权模式并在相同的内存空间内运行。尽管能添加/移除和启动/关闭设备驱动程序,但仍要注意确保在关闭设备时适当释放系统资源。
3.2.3.2 QNX Neutrino
虽然多数操作系统都要求牢固绑定设备驱动程序,但 QNX Neutrino 的设备驱动程序却能像标准进程那样启动和关闭。因此,添加设备驱动程序不会影响操作系统的任何部分,可像其他应用程序那样行开发和调试驱动程序。
在 QNX Neutrino 中,只有特定进程才允许执行特定的操作(如附加中断)。这些进程需要取得输入/输出特权,即与能控制硬件输入/输出端口等有关的特权。只有根账户才能取得输入/输出特权。
3.2.3.3 结论
- 在 QNX Neutrino 与 VxWorks 中,向操作系统集成设备驱动程序时采用的机制(和设备驱动程序因此要实现的应用程序接口)有很大区别。这意味着,当从 VxWorks 向 QNX Neutrino 移植时,多数设备驱动程序都需要重写。
- 当编写可直接访问 QNX Neutrino 硬件的代码时,必须注意确保正确设置内存访问(共享内存)、寻址(必须在应用程序地址和物理内存地址之间转换)、内存分配(必须重视缓存一致性),以及特权/许可权(输入/输出特权、根许可权)。
3.3 网络
VxWorks 5.4 / 5.5 中的 IP 网络协议栈是基于 BSD 4.4 实现的;QNX Neutrino网络协议栈是基于 NetBSD 4.0 的。它们的架构有很多相似之处,因而可确保按下面介绍的那样重用设备驱动程序。
3.3.1 VxWorks 网络架构
标准 VxWorks 网络架构分为三个组件级:设备驱动程序、多路复用 (MUX) 层和网络协议栈
图14:VxWorks 的网络架构。
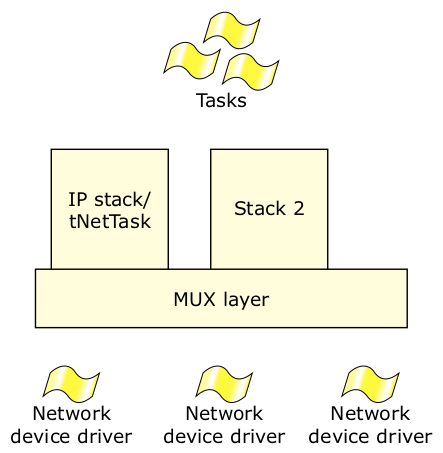
网络设备驱动程序通过接口直接连接网络硬件,并生成发送至下一层的数据包。用户提供的设备驱动程序必须提供一个与多路复用 (MUX) 层架构一致的应用程序接口。可选择两种形式的驱动程序: END 驱动程序(帧导向)或 NPT 驱动程序(数据包导向)。两种应用程序都要求用户使用具有下列函数的应用程序接口:
- load/unload()——向多路复用 (MUX) 层附加/或从多路复用 (MUX) 层脱离驱动程序
- send()——将数据发送到物理层上
- mcastAddrAdd/Del/Get()——多播地址函数
- PollSend/Receive()——以轮询模式(而非中断驱动模式)发送数据包/帧
- start/stop()——启动或关闭设备(包括中断处理程序)
- bind()——连接至协议栈内
- ioctl()——输入/输出命令支持函数
除这些函数外,您还能使用 muxAddrResFuncAdd/Get/Del() 函数集加入用于协议/接口的地址解析函数。
网络设备的缓冲管理是通过 netBufLib 库调用处理的。该程序库为用户提供了建立和管理设备级缓冲区(以接收和发送数据)所需的所有工具。
注意,这里没有“中断接收”应用程序接口。这是使用中断处理程序内部的 netJobAdd() 函数调用处理的,以接收设备发送的数据包。END 与 NPT 数据包的主要区别是,NPT 驱动程序会从接收的数据包中摘除数据链头信息,然后将其发送至多路复用 (MUX) 层,而 END 驱动程序含有以太网头信息。
多路复用 (MUX) 层实质上位于 OSI 网络模型内的数据链层和网络层之间。可使用函数 muxBind/muxTkBind() (ipAttach) 将高层协议栈连接到多路复用(MUX) 层中,并使用函数 muxUnbind() (ipDetach)中断它们的连接。从应用程序的角度看,muxBind/muxUnbind() 例程很有用,在原始数据包进入 IP 协议栈前,它能确保用户“捕捉”到该数据包并进行处理(常用术语称为“诱捕”)。
位于多路复用 (MUX) 层上的是一个或多个网络协议栈,它们依附在多路复用 (MUX) 层上,使指定的设备接收用于协议栈的数据包,或发送来自协议栈的数据包。 VxWorks 中使用的标准 IP 协议栈使用 ipAttach/ipDetach() 附加到多路复用 (MUX) 层中。
可使用全局变量配置 IP 协议栈的运行特性(如不中断超时、 ARP 超时等)。
3.3.2 QNX Neutrino 网络架构
与 QNX Neutrino 中其他提供服务的进程一样,网络服务也是在内核外部执行的。系统提供了一个独立统一的接口,而不考虑涉及到的网络配置和数量。这种架构允许网络驱动程序以动态方式启动和关闭;Qnet、TCP/IP 和其他协议能以任何组合方式一同运行。
图15:QNX Neutrino 的网络架构。

本机网络子系统包括网络管理器可执行文件 (io-pkt),以及一个或多个共享库模块。这些模块可包含协议(如 lsm-qnet.so )、驱动程序(如devn-ne2000.so)和过滤器(如 lsm-pf-v6.so)。io-pkt 有三种变体:
io-pkt-v4
IPv4 版协议栈无内建的加密或无线保真 (Wi-Fi) 功能。这是一种“外形精简”版的协议栈,它不支持以下内容:
- IPv6
- Crypto / IPSec
- 802.11 a/b/g WiFi
- 桥接
- GRE / GRF
- 多址通信路径选择
- 多点端对端协议 (PPP)
io-pkt-v4-hc
IPv4 版协议栈具有内建完整的加密和无线保真 (Wi-Fi) 功能,包括硬件加速密码功能 (Fast IPsec)。
io-pkt-v6-hc
IPv6 版协议栈(包括作为 v6 组成部分的 IPv4)具有完整的加密和无线保真 (Wi-Fi) 功能和硬件加速密码功能。
io-pkt 协议栈的架构与 QNX Neutrino 操作系统内的其他组件子系统非常相似。位于底层的驱动程序可提供数据传送(向硬件)和数据接收(从硬件)机制。驱动程序进入到多线程 2 层组件中(这也提供了快速转发和桥接功能)使彼此密切连接,并提供了统一接口进入 3 层组件,然后处理单独的 IP 和上层协议处理组件(TCP 和 UDP)。
图16:io-pkt 架构。
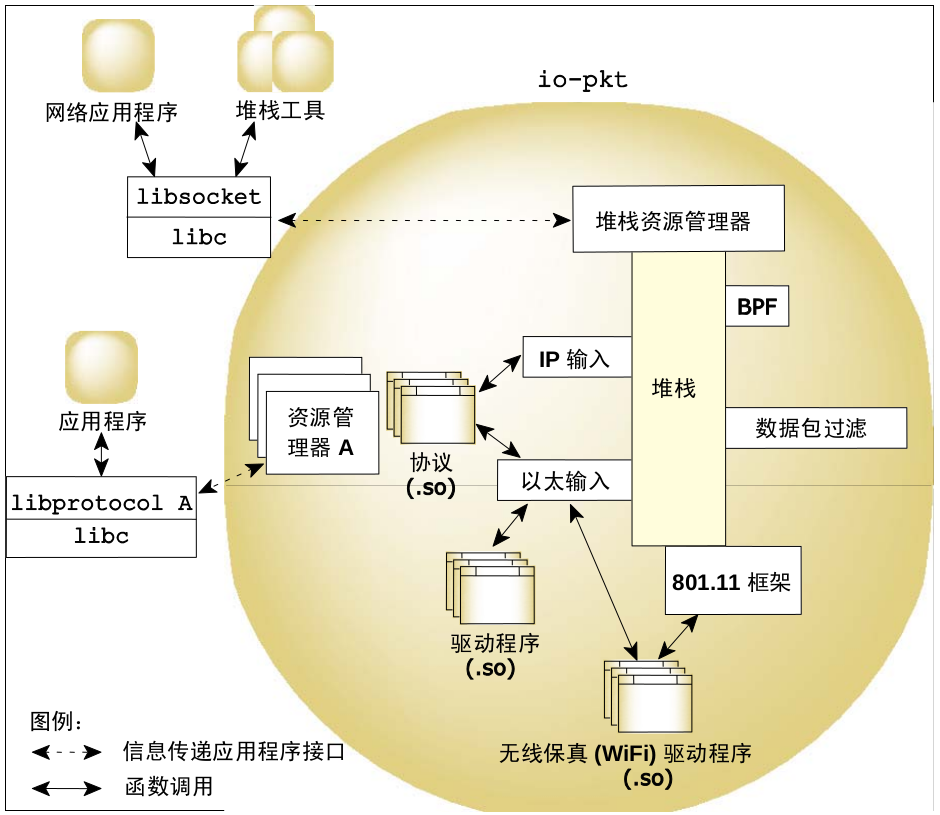
资源管理器在协议栈顶部形成一个层并充当协议栈与用户应用程序之间信息传递媒介。它提供了标准类型的接口(包括 open()、read()、write() 与 ioctl()),该接口可使用信息流与网络应用程序通信。用户编写的网络应用程序可链接套接字库。套接字库可将协议栈暴露的信息传递接口转换成标准的 BS式套接字层应用程序接口,它是目前大部分网络代码的标准接口。
除了套接字层应用程序接口外,还在协议栈中加入了其他的编程接口,以实现其他协议或进行过滤。
在驱动程序层,还有用于以太网传输的接口(供所有以太网驱动程序使用)和加入协议栈(面向来自无线驱动程序 802.11 管理帧)的接口。协议栈的hc变体还包括单独的硬件加密应用程序接口,确保协议栈在针对安全链接加密或解密时能使用加密卸载引擎。
io-pkt 组件是网络系统内的活动可执行文件。io-pkt 可充当一种转向器/多路器,负责根据在其命令行(或在启动后通过 mount 命令)指定的配置加载协议和驱动程序模块。由于采用了零复制架构,因此 io-pkt 可执行文件能在运行中有效地加载多个网络协议、过滤器或驱动程序(如 lsm-qnet.so、lsm-autoip.so)——这些模块是安装在 io-pkt 内的共享对象。
网络协议模块负责实现特定协议(如 Qnet 等)的细节部分。每个协议组件都会作为共享对象进行封包(如 lsm-qnet.so)。一个或多个协议组件能并行运行。io-pkt 运行时,您能使用 mount 命令在命令行以动态方式加载驱动程序。例如,这些命令:
io-pkt-v6-hc &
mount -T io-pkt devnp-e1000.so
会启动 io-pkt,然后安装用于英特尔千兆以太网控制器的驱动程序。载入共享对象后, io-pkt 会对其进行初始化。驱动程序和 io-pkt 就能有效地绑定在一起,驱动程序会调用 io-pkt (例如,当来自接口的数据包到达时),而且io-pkt 也会调用驱动程序(例如,当需要从应用程序向接口发送数据包时)。您也可以使用 ifconfig 命令卸载驱动程序。
ifconfig wm0 destroy
您可专门针对 io-pkt 编写驱动程序或移植一个 NetBSD 驱动程序。甚至还有一个“填充”层,允许您使用为早期网络协议栈编写的驱动程序,io-net。
3.3.2.1 QNX Neutrino sysctl()接口
函数 sysctl() 可检索系统信息并允许具有适当特权的进程设置系统信息。sysctl()中的可用数据由整数和表格组成。您也可以使用命令行的 sysctl 工具取得或设置数据。
以下是您使用 QNX Neutrino 中的 sysctl()接口能修改的一些参数:
| 可使用 sysctl() 修改的协议栈参数 | 说明 |
| ip.forwarding | 当针对主机启用 IP 转发时,返回 1,表示主机目 前正充当路由器。 |
| ip.redirect | 当主机可发送 ICMP 转向时,返回 1。该选项可忽 略,除非主机正在发送 IP 数据包。通常,该选项 应在所有系统上启用。 |
| ip.ttl | 系统提供的 IP 数据包的最大生存时间(跳数)值。 该数值适用于常规传输协议,不适用于 ICMP。 |
| ip.forwsrcrt | 当针对主机启用源路由数据包转发时,返回 1。只 有当内核的安全级别小于 1 时才能更改该数值。 |
| ip.directed-broadcast | 当针对主机启用直接广播运行时,返回 1 |
| ip.allowsrcrt | 如果主机接受源路由数据包,返回 1。 |
| ip.subnetsarelocal | 如果子网被认为是本机地址,返回 1 |
| ip.mtudisc | 如果启用了路径最大传输单元发现,返回 1 |
| ip.maxfragpackets | 返回位于 IP 重组队列中的数量最多的分段 IP 数 据包。 |
| ip.sourcecheck | 如果启用了针对接收数据包的来源检查,返回 1 |
| ip.sourcecheck_logint | 当记录 IP 来源地址验证信息后,返回时间间隔。 将其设置为零会关闭记录功能。 |
| icmp.maskrepl | 如果 ICMP 网络掩码得到答复,返回 1 |
| tcp.rfc1323 | 如果启用了针对 TCP 的 RFC1323 扩展,返回 1 |
| tcp.sendspace | 返回默认的 TCP 发送缓冲器规格。 |
| tcp.recvspace | 返回默认的 TCP 接收缓冲器规格。 |
| tcp.mssdflt | 返回默认的 TCP 最大数据片长度。 |
| tcp.syn_cache_limit | 返回 TCP 压缩状态引擎内允许的最多条目数。 |
| tcp.syn_bucket_limit | 返回 TCP 压缩状态引擎内允许的每个散列桶的最 多条目数。 |
| tcp.syn_cache_interval | 返回 TCP 压缩状态引擎的时间间隔。 |
| udp.checksum | 当计算并检查 UDP 检查和时,返回 1。 注意: 严禁停用 UDP 检查和。 |
| udp.sendspace | 返回默认的 UDP 发送缓冲器规格。 |
| udp.recvspace | 返回默认的 UDP 接收缓冲器规格。 |
3.3.3 结论
- 如前几节所述,设备驱动程序需要重新实现以与 io-pkt 基础结构正确集成。
- 您可以使用本机 io-pkt 驱动器、移植的 NetBSD 驱动程序或遗留的io-net 驱动程序。
- VxWorks 中应用层的应用程序接口是基于 BSD 4.4 实现的;QNXNeutrino 应用程序接口是基于 NetBSD 4.0 的。这样,就能直接从VxWorks 向 QNX Neutrino 移植大部分应用层代码。还需要进行少许改动(如设备名称)以完成移植。
- 在使用 ioctl 命令对协议栈进行控制和配置方面,两种系统有相似之处。相似度部分取决于底层设备驱动程序的实现方式。某些 VxWorks应用程序接口调用提供的运行,都能在 QNX Neutrino 中使用 ioctl 接口获得,如下所示。
| VxWorks 应用 程序接口: | QNX Neutrino ioctl() 等效接口: |
| ifAddrAdd() | ioctl(SIOCAIFADDR, struct ifaliasreq *req) |
| ifAddrSet() | ioctl(SIOCSIFADDR, struct ifreq *req) |
| ifAddrGet() | ioctl(SIOCGIFADDR, struct ifreq *req) |
| ifBroadcastSet() | ioctl(SIOCSIFBRDADDR, struct ifreq *req) |
| ifBroadcastGet() | ioctl(SIOCGIFBRDADDR, struct ifreq *req) |
| ifDstAddrSet() | ioctl(SIOCSIFDSTADDR, struct ifreq *req) |
| ifDstAddrGet() | ioctl(SIOCGIFDSTADDR, struct ifreq *req) |
| ifMaskSet() | ioctl(SIOCSIFNETMASK, struct ifreq *req) |
| ifMaskGet() | ioctl(SIOCGIFNETMASK, struct ifreq *req) |
| ifFlagSet() | ioctl(SIOCSIFFLAGS, struct ifreq *req) |
| ifFlagGet() | ioctl(SIOCGIFFLAGS, struct ifreq *req) |
| ifMetricSet() | ioctl(SIOCSIFMETRIC, struct ifreq *req) |
| ifMetricSet() | ioctl(SIOCGIFMETRIC, struct ifreq *req) |
- 两种系统在修改协议栈运行的特定方面(不中断计时器、 ARP 超时等)上不同。在 VxWorks 中,您能修改全局变量;在 QNX Neutrino 中,您能使用 sysctl()接口修改多个此类参数。
3.3.4 网络应用程序编程
3.3.4.1 协议与 RFC 标准支持。
QNX Neutrino 支持多种网络协议和 RFC 标准,包括(但不限于)以下部分:
| TCP/IP 协议栈支持的 RFC 标准 (与 io-pkt-v6-hc 有关) | 标题 |
| 2367 | PF_KEY 密钥管理应用程序接口,第 2 版 |
| 1826; 2402 | IP 认证报头 |
| IP 认证报头 | 在封装安全载荷 (ESP) 与认证报头 (AH) 范围内使用 HMAC-MD5-96 |
| 2404 | 在封装安全载荷 (ESP) 与认证报头 (AH) 范围内使用 HMAC-SHA-1-96 |
| 2405 | 带 Explicit IV 的 ESP DES-CBC 密码算法 |
| 2406 | IP 封装安全载荷 (ESP) |
| 2292 | 适用于 IPv6 的高级套接字应用程序接口 |
| 2553 | 适用于 IPv6 的基本套接字接口扩展 |
| 2463 | 适用于第 6 版互联网协议 (IPv6) 规范的互联网控制 信息协议 (ICMPv6) |
| 2460 | 第 6 版互联网协议 (IPv6) 规范 |
| 2461 | 适用于第 6 版互联网协议 (IPv6) 的邻居发现协议 |
| 2462 | IPv6 无国界地址自动配置 |
| 2451 | ESP CBC-Mode 密码算法 |
| 1981 | 适用于第 6 版互联网协议 (IPv6) 的路径最大传输单 元发现 |
| 2373 | 第 6 版互联网协议 (IPv6) 的寻址体系架构 |
| 2144 | CAST-128 加密算法 |
| 2401 | 互联网协议的安全体系架构 |
| 2960 | 流控制传输协议 (SCTP) |
| 2526 | 预留的 IPv6 子网随播地址 |
| 2374 | IPv6 全局单播地址格式 |
| 2375 | IPv6 多播地址分配 |
| 2473 | IPv6 规范中的常规数据包通道技术 |
| 2464 | 通过以太网络传输 IPv6 数据包 |
| 2893 (portions of) | 适用于 IPv6 主机和路由器的转换机制 |
| 1701 | 通用路由封装 (GRE) |
| 1702 | 在 IPv4 网络上的通用路由封装 |
io-pkt 的所有三种 Profile 都支持以下 RFC 标准:
| TCP/IP 协议栈支持的 RFC 标准(io-pkt-v4、io-pkt-v4-hc 与 io-pkt-v6-hc) | 标题 |
| 791 | 互联网协议-DARPA 互联网程序-协议规范 |
| 792 | 互联网控制信息协议-DARPA 互联网程序-协议规 范 |
| 793 | 传输控制协议 (TCP) |
| 768 | 用户数据报协议 |
| 1122 | 互联网主机要求——通信层 |
| 2001 | TCP 慢启动、拥塞避免、快速重传与快速恢复算法 |
| 1112 | 适用于 IP 多播的主机扩展 |
| 1323 | 针对高性能的 TCP 扩展 |
网络应用程序支持下列 RFC 标准:
| 应用程序支持的 RFC 标 准 | 标题 |
| 1123 | 互联网主机的要求——应用与支持 |
| 1700 | 分配数目 |
| 951 | 引导协议 (BOOTP) |
| 2409 | 互联网密钥交换协议 (IKE) |
| 1542 | 引导协议的澄清与扩展 |
| 1048; 1084 | 引导协议供应商信息的扩展 |
| 854 | 远程登录协议规范 |
| 1408; 1572 | 远程登录环境选项 |
| 959 | 文件传输协议 (FTP) |
| 2389 | 适用于文件传输协议的功能协商机制 |
| 2428 | 针对 IPv6 与 NAT 的 FTP 扩展 |
| 2732 | URL 内 IPv6 字面地址的格式 |
| draft-ietf-ftpext-mlst-16.txt | FTP 扩展 |
| 1350 | 一般文件传输协议(修订版 2) |
| 1035 | 域名——执行与规范 |
| 1058 | 路由信息协议 |
| 1723 | 含有补充信息的第 2 版路由信息协议 (RIP) |
| 2080 | 适用于 IPv6 的下一代路由信息协议 (RIPng) |
| 1256 | ICMP 路由器发现信息 |
| 1094 | 网络文件系统协议规范 (NFS) |
| 1813 | 第 3 版 NFS 协议规范 |
| 1831 | 第 2 版远程过程调用协议规范 (RPC) |
| 1832 | 外部数据表示标准 (XDR) |
| 1833 | 适用于第 2 版 ONC RPC 的绑定协议 |
| 2131 | 动态主机配置协议 (DHCP) |
| 2132 | DHCP 选项与 BOOTP 供应商信息扩展 |
| 882 | 域名——概念与工具 |
| 883 | 域名——执行与规范 |
| 931 | 认证服务器 |
| 973 | 域名系统更改与观察 |
| 974 | 邮件路由与域名系统 |
| 1033 | 域管理员操作指南 |
| 1034 | 域名——概念与工具 |
| 1035 | 域名——执行与规范 |
| 1075 | 距离向量组播路由协议 |
| 1144 | 适用于低速串行链路的压缩 TCP/IP 报头 |
| 1321 | MD5 信息摘要算法 |
| 1332 | 端对端互联网协议控制协议 (IPCP) |
| 1334 | 端对端协议的认证协议 |
| 1549 | HDLC 组帧中的端对端协议 |
| 1661 | 端对端协议 (PPP) |
| 1662 | HDLC 式组帧中的端对端协议 |
| 1962 | 端对端协议的压缩控制协议 (CCP) |
| 1990 | 多重链路端对端协议 (MP) |
| 2068 | 超文本传输协议——HTTP/1.1 |
| 1305 | 网络时间协议(第 3 版)规范、执行与分析 |
| 2030 (obsoletes RFC 1769, which obsoletes RFC 1361) | 适用于 IPv4、IPv6 与 OSI 的第 4 版简单网络时间协议 (SNTP) |
| 1119 | 网络时间协议(第 2 版)——规范、执行与分析 |
注意,虽然 io-pkt-v6-hc 支持以上所有协议,但 io-pkt-v4 与 io-pkt-v4-hc 支持子集:
- IP, UDP, TCP, ICMP, ARP, IPv6, IPSec, SCTP, ICMPv6, IGMPv2
- IP, UDP, TCP, ICMP, ARP, IPv6, IPSec, SCTP, ICMPv6, IGMPv2
- Unix 域套接字
- PROXY ARP (仅针对端对端接口)
- VPN - GRE (通用路由封装):
− GIF (通道 Pv4 IPv6,如 IPv4 上的 IPv6)
− VLAN (IEEE 802.1Q 虚拟局域网)
- 动态链接库 (DLL) 支持
- PPP, PPPOE, SCTP, NAT/IPfilter, QNET, AutoIP
- 应用程序支持
- 引导协议(仅针对服务器)
- DHCP(服务器、客户端和中继代理)
- SNMP v1, v2p(CMU 源代码库端口)
- SRI SNMP v1, v2c, v3 (SNMP 研究端口)
- HTTP1.1/CGI1.1/SSI (仅针对小型服务器)
- NFS v2, v3 (服务器与客户端)
- PCNFSD
- CIFS/SMB (仅针对客户端)
- FTP (客户端与服务器)
- 远程登录(客户端与服务器)
- TFTP(客户端与服务器)
- DVMRP
- RIP v1, v2, RIPng
- PPP/PAP/CHAP
- PPPOE(仅针对客户端)
- NTP v2, v3, v4
- SOCKS
- LPR
- RLOGIN
- IKE ((参见 “racoon” 二进制文件了解可用性)
3.3.4.2 套接字编程
VxWorks 使用的套接字层应用程序接口是基于 BSD 4.4 的; QNX Neutrino 中的相应接口是基于 NetBSD 4.0 的。由于两种程序库之间使用的代码库不同,因此需要修改代码以推动移植的顺利进行,但工作量应该不会很大。在 QNX Neutrino 中,适用于 TCP/IP 协议栈的应用程序接口包括 BSD 套接字应用程序接口、路由套接字、sysctl()、kvm*()与 PF_KEY 套接字,它们都有助于移植的顺利进行。根据协议的不同,集成也有所变化。许多协议都会使用上述可移植性极佳的接口。
3.3.4.3 VxWorks
VxWorks 包括许多编程应用程序接口,用于直接连接应用程序和网络工具。VxWorks 中有许多可提供网络工具的模块。这些包括: DHCP、 PPP、 ProxyARP、FTP、TFTP 以及远程登录服务器。
3.3.4.4 QNX Neutrino
QNX Neutrino 提供了上述所有工具(以及远程登录客户端应用程序)的实现。但它们通常都是作为无法直接从源程序中调用的应用程序(如二进制图像)的形式提供的。可使用标准 Unix 机制从命令行调用应用程序。如果需要在应用程序中嵌入工具,还能使用所有工具的源代码。这通常是不需要的,因为能使用更简单的机制调用所需的工具。顺便说明一下,借助 QNX Neutrino 功能全面的远程登录服务器和完全可重入的外壳,多个客户端能同时接入目标机。
3.3.4.5 结论
- VxWorks 为网络工具提供了编程接口。
- QNX Neutrino 为网络工具提供了二进制可执行文件。通常都是使用命令行解释器提供的脚本调用它们的。必要时,可将工具的源代码加入应用程序代码中。
- QNX Neutrino 还有 VxWorks 无法提供的其他工具。
3.4 应用程序的移植
本节中提到的“应用”层是指在很大程度上跨硬件的应用程序部分。如上所述,在 VxSim (开发过程中广泛使用的产品)和目标机平台中运行的应用程序应能通过移植库直接移植到 QNX Neutrino 中。
3.4.1 vx2qnx.lib 概述
为方便从 VxWorks 向 QNX Neutrinoa 进行遗留代码的初始移植,在基于VxWorks 的现有应用程序代码和底层 QNX Neutrino 基元之间提供了一个移植库作为中间“纽带”。
图17:VxWorks 遗留程序。
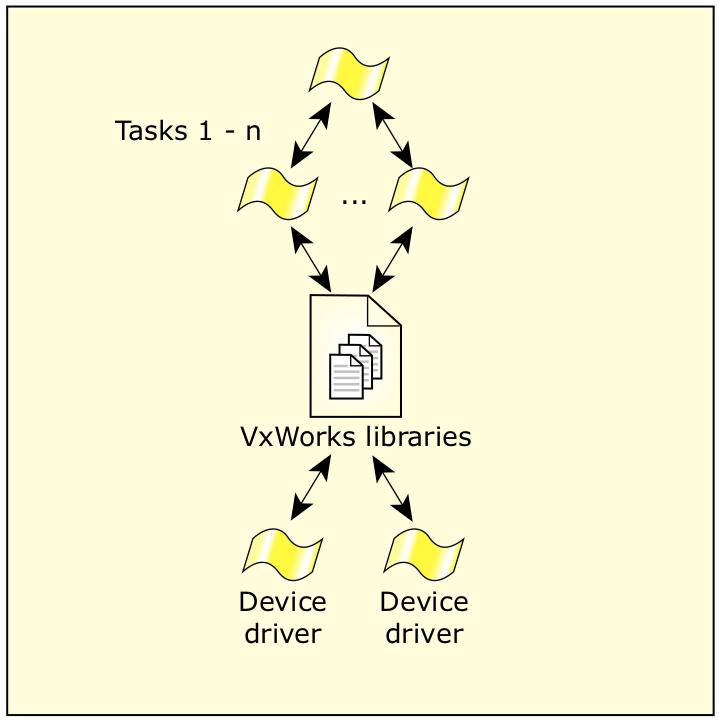
vx2qnx 移植库包含多种常用 VxWorks 应用程序接口函数(使用底层 QNX Neutrino 基元)的实现。这可确保代码与现有的遗留代码(依赖应用层的VxWorks 应用程序接口)实现兼容。您可在我们的 Foundry27 网站上,查看Wind River 公司 VxWorks 迁移项目中的 vx2qnx 移植库,网址是 http://community.qnx.com 。
图18:移植到 QNX Neutrino 中的 VxWorks 遗留程序。
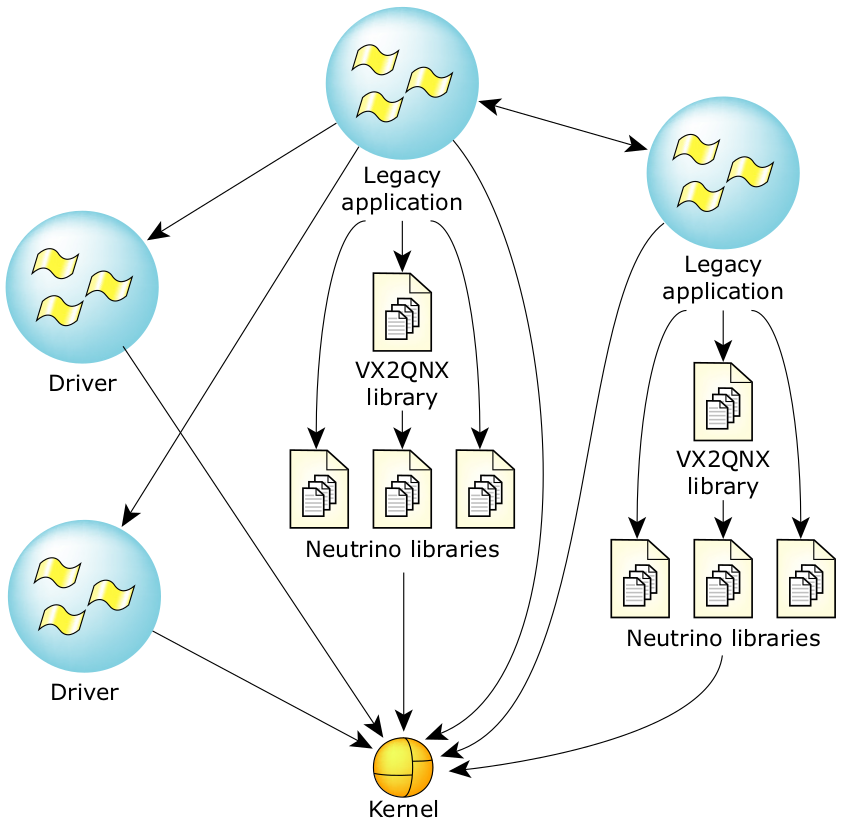
移植库的功能包括任务运行、信号量、信息队列、监视程序定时器、列表处理例程等。上述所有功能都可通过 QNX Neutrino 基元实现,以提供与VxWorks 提供的功能完全一样的功能。这样就能实现遗留代码的兼容性,而无须进行大量的重新编码工作。 vx2qnx 移植库实现是以源代码的形式提供的。
注意:还有一种直接但更详细的方法(如下所述)可将调用转换为 VX 移植库中的函数,即以函数的形式将它们映射到底层 QNX Neutrino 基元中,这是一种理想的替代方案。该方法可确保使用 QNX Neutrino 中的本机机制以更接近的方式实现代码。
提供移植层可确保最大限度减少初始移植的工作量,而且还能显示如何使用本机 QNX Neutrino 基元实现具体的 VxWorks 功能。通常,用户都会开展更为详尽的移植工作,这不仅限于代码和应用程序接口的兼容性,还包括具体的架构设计修改,以充分利用 QNX Neutrino 架构的多种固有优势。
vx2qnx 移植库在 QNX Neutrino 中提供了可实现应用程序接口调用(类似于在 VxWork 中进行的)接口代码。如果底层基元无法提供完全一致的运行方式,实现将在移植库内进行。这会导致性能损失,因为在进行调用的应用程序和实现调用的操作系统之间还有附加层。
使用 vx2qnx 移植库就能将整个 VxWorks 系统实现为独立的 QNX Neutrino 进程:VxWorks 中的每个任务都会映射为 QNX Neutrino 中不同线程,但所有线程都位于同一进程内。该模式的不利方面是,系统无法充分利用 QNXNeutrino 进程间的内存保护功能。(欲了解有关 QNX Neutrino 与 VxWorks 实现的运行差别的信息,请参加本文件附录中的 5.2 节。)
下列应用程序接口可在移植库内实现:
| VxWorks 移植库 | 函数 |
| taskLib | taskSpawn(), taskInit(), taskActivate(), exit(), taskDelete(), taskDeleteForce(), taskSuspend(), taskResume(), taskRestart(), taskPrioritySet(), taskPriorityGet(), taskLock(), taskUnlock(), taskSafe(), taskUnsafe(), taskDelay(), taskIdSelf(), taskIdVerify(), taskTcb() |
| msgQLib | msgQLibInit(), msgQCreate(), msgQDelete(), msgQSend(), msgQReceive(), msgQNumMsgs() |
| semLib | semLibInit(), semGive(), semTake(), semFlush(), semDelete() |
| semMLib | semMLibInit(), semMCreate() |
| semCLib | semCLibInit(), semCCreate() |
| semBLib | semBLibInit(), semBCreate() |
| wdLib | wdCreate(), wdDelete(), wdStart(), wdCancel() |
| errnoLib | errnoGet(), errnoOfTaskGet(), errnoSet(), errnoOfTaskSet() |
| taskInfoLib | taskName(), taskNametoId(), taskIdDefault(), taskIsReady(), taskIsSuspended(), taskIdListGet() |
| kernelLib | kernelInit(), kernelTimeSlice(), kernelVersion() |
| lstLib | lstInit(), lstAdd(), lstConcat(), lstCount(), lstDelete(), lstExtract,lstFirst(), lstGet(), lstInsert(), lstLast(), lstNext(), lstNth(), lstPrevious(), lstNStep(), lstFind(), lstFree() |
QNX Neutrino 通过符合相同的 POSIX/Unix 调用实现,已经支持下列VxWorks 移植库:
| VxWorks 移植库 | POSIX/Unix 函数 |
| schedPxLib | sched_setparam(), sched_getparam(), sched_setscheduler, sched_getscheduler(), sched_yield(), sched_get_priority_max, sched_get_priority_min(), sched_rr_get_interval() |
| mqPxLib | mq_open(), mq_receive(), mq_send(), mq_close(), mq_unlink(), mq_notify(), mq_setattr(), mq_getattr() |
| clockLib | clock_getres(), clock_setres(), clock_gettime(), clock_settime() |
| semPxLib | sem_init(), sem_destroy(), sem_open(), sem_close(), sem_unlink(), sem_wait(), sem_trywait(), sem_post(), sem_getvalue() |
| sigLib | sigemptyset(), sigfillset(), sigaddset(), sigdelset(), sigismember(), signal(), sigaction(), sigprocmask(), sigpending(), sigsuspend(), pause(), sigtimedwait(), sigwaitinfo(), sigsetmask(), sigblock(), raise(), kill(), sigqueue() |
| timerLib | timer_cancel(), timer_create(), timer_delete(), timer_gettime(), timer_getoverrun(), timer_settime(), nanosleep() |
4 构建环境
建立一个构建环境以生成构建映像需要付出大量的精力。幸运的是, VxWorks 与 QNX Neutrino 都能使用 GNU 工具链,因此您能借助 QNX Neutrino 重复使用 VxWorks 构建环境的元素。
本节将为您介绍从 VxWorks 向 QNX Neutrino 迁移构建环境时可能出现的一些问题。
4.1 生成文件
将构建环境从一种系统改到另一种系统需要付出的努力,显然取决于构建过程的复杂性。对小型构建而言,最简单的办法是重新编写进入构建的生成文件。 QNX Neutrino 提供了一套完整的生成文件,用于(经过适当修改)以递归方式建立目录树。
QNX Momentics 集成开发环境(类似 Tornado)也可用于自动生成并管理小型项目的生成脚本。
对于大型复杂的构建而言,如果以采用提取工具链的方式编写脚本,就可重复使用已有生成脚本的一部分。在 VxWorks 生成文件中,通常使用宏命令定义适当的命令行用于归档、编译、链接等。在吸收了适当的 QNX Neutrino .mk 文件后,可使用对应的 QNX Neutrino 命令替换这些宏命令。
还可能需要修改生成脚本以说明 make 版本的区别(尽管这并不多)并支持系统工具。例如,微软 Windows 平台上的构建过程包含 cygwin 工具集(用于构建 VxWorks [使用 cygwin])很常见。这就为 MS-Windows 提供了一种类似 Unix 的命令集,用于在不同的构建平台上保持一致性。cygwin 工具的运行取决于共享库 (cygwin1.dll)。QNX Neutrino 使用了“用于 Windows 的最低要求的 GNU (MinGW)” 和“最小系统 (MSYS)”
注意:应注意确保 PATH 变量中包含 cygwin1.dll 的正确位置以防止版本冲突。
4.2 C/C++ 编译器
两种操作系统都将 GNU C/C++ 编译器用作标准编译器。5.4 版 VxWorks 使用了 2.7.2 版编译器, 5.5 版使用了 2.96+ 版(2.95 版实质上具有 Wind River 公司的新增功能)。 QNX Neutrino 6.3 版使用了 3.3 版编译器(也支持 2.95 版),QNX Neutrino 6.4.1 版使用了 4.3 版编译器。
两种 VxWorks 5.4 工具链的用户在通过 QNX Momentics 工具套件使用的编译器传递代码时,编译器会出现问题。特别是,GNU 编译器中已启用了更严格的类型检查规则。这本身就要求为 2.7.2 版编译器可接受的函数参数提供一种正确的类型转换。
在向 QNX Neutrino 移植时出现的大部分编译器问题,应该与从 VxWorks 5.4向 5.5 移植时遇到的问题完全相同,因为 VxWorks 5.5 与 QNX Neutrino 的编译器工具链都是源自相同的代码库。
QNX Neutrino 与 VxWorks 5.5 提供的编译器工具链的细微变化都会导致所需的代码变化,从而影响原始编译。
使用 Diab 工具链的 VxWorkstool 环境也会由于编译器的不同而遇到所需代码发生变化的情况。
虽然许多标准程序库都具有固定的应用程序接口 (API),但其他(如 C++ 标准模板库 [STL])一些程序库已随时间的迁移不断发展。对于使用更早版本程序库的 VxWorks 而言,可能需要进行代码修改以适应新的程序库。注意,QNX Momentics 工具套件包括两种版本的标准模板库 (STL) : GCC 与Dinkum。Dinkum 库是 Dinkumware 公司开发的标准模板库的“无尘室”实现。(www.dinkumware.com ),它不会产生相关的通用公共许可 (GPL) 问题。
4.3 链接器
在 VxWorks 中,可在开发阶段引入一些链接产品。这包括部分链接的“可下载”模块(能下载并动态地链接到运行的应用程序中)和完整的应用程序映像(包括操作系统)。VxWorks 中的建立过程通常包括编译并建立对象模块、部分链接对象文件以生成模块,然后执行各种步骤(如“以混合方式”检索构造函数/析构函数信息)以生成一个用于单元测试的可下载模块。
对于最终产品,模块会依次“部分地”链接到一起组成一个“部分映像”对象文件(包括操作系统库)。然后对该对象文件进行分析以获取其他各类信息(构造函数/析构函数、符号表等),以进入最终链接阶段。最终链接阶段会产生完整的应用程序映像。
对 QNX Neutrino 而言,应用程序建立阶段的最终结果是产生 应用程序映像,而非操作系统映像。就这样,链接阶段包括获取编译的对象文件 (.o),再将它们与操作系统库链接到一起形成应用程序映像(即与“桌面”运行环境相同)。然后可使用外壳命令或脚本将该映像上传到目标中并执行。在自托管 (self-hosted) 的开发环境中,用户能立即从命令行执行 x86 目标应 用程序。
与 VxWorks 不同,这里无需“混合”不完整的 C++ 映像文件以检索构造函数/析构函数信息(因为与操作系统的启动不同,设置静态构造函数/析构函数是在应用进程启动的过程中完成的)。针对所有单独进程形成完整的可执行映像意味着开发人员应利用代码(可在进程间共享)的动态链接功能以减少内存使用。我们将在下节为您介绍这一需要考虑的问题。
当所有应用程序映像都建立之后,可将它们放入操作系统映像(使用映像文件系统)中,或将它们作为单独实体储存在其他文件系统中,以便在运行时调用。在外壳的命令执行使用了安装的文件系统(由 PATH 环境确定)搜索,以查找显示的映像完成执行(仍与桌面系统相同)。
最后提示一点: QNX Neutrino 的每个单独进程都必须添加一个函数 main() 以指出链接器(应用程序开始运行的地方)。函数 main() 会初始化应用程序并以适当方式启动线程。
4.4 应用程序内存的使用
在 VxWorks 5.4/5.5 中,由于全部地址空间对所有任务都是可见的,因此“代码共享”是以透明方式实现的(在代码设计时应特别注意处理重入问题)。这允许多个线程共享内存中的相同代码。在 QNX Neutrino 内的单独进程中也存在这种功能。但在 QNX Neutrino 内的多个进程之间,内存隔离/虚拟内存实现利用“正常”应用程序代码阻止了这种情况的发生(即无法在两 个进程之间传递函数地址,并让第二个进程运行该函数)。使用正常的链接进程,可以静态方式将对象链接到一起形成最终映像。如果多个进程需要相同代码,那么每个映像中都会包含自己的代码备份。
这对内存利用有重要意义(无论是对在闪存中储存映像还是在运行的随机存储器 [RAM] 中储存可执行文件)。可通过将软件库变成共享对象或动态链接库的方式对其进行共享。这就能使多个进程以动态方式链接到库中,因而减少了内存需求。还可使用共享库对应用程序进行动态升级。如果采用多进程方案从 VxWorks 向 QNX Neutrino 移植应用程序,应检查代码库以 确定是否应将其一部分集中到共享库中。
5 附录
5.1 移植参考
下表列出了 VxWorks 中的程序库与 QNX Neutrino 中的程序库/调用之间在功能上的大致对应关系:
| VxWorks | QNX Neutrino/POSIX |
| taskLib | pthread_*, posix_spawn_*, fork |
| semCLib, semLib, semMLib, semBLib, semPXLib | sem_*, pthread_mutex_*, pthread_cond_*, pthread_sleepon_*, pthread_barrier_*, pthread_rwlock_* |
| msgQLib, msgPXLib | mq_*, MsgSend/MsgReceive, MsgSendPulse |
| taskVarLib | pthread_key_* |
| sigLib | sig* |
| sockLib | libsocket |
| wdLib, timerLib | timer_*, SIGEV_* |
| schedPxLib | sched_*, pthread_*; Sporadic Scheduling Policy. |
| ansiAssert, ansiCtype, ansiLocale, ansiMath, ansiSetjmp, ansiStdarg, ansiStdio, ansiStdlib, ansiString, ansiTime | 主要位于 libc 内(标准 Unix/POSIX) |
| clockLib | clock_* (libc) |
| dirLib | 主要位于 libc 内(标准 Unix/POSIX) |
| fioLib | 主要位于 libc 内(标准 Unix/POSIX) |
| hostLib | 主要位于 libsocket 内 |
| ioLib | 主要位于 libc 内(标准 Unix/POSIX) |
| resolveLib | 主要位于 libsocket 内 |
| memPartLib | malloc, free, shm_*, mmap/munmap |
5.2 运行区别
5.2.1
taskSwitchHookj
现有的 taskVariables 呼叫能映射为 pthread_key_*() 呼叫,但 VxWorks 的任务变量 能直接访问/修改每个任务上下文中的变量,而无需通过任务变量接口。
另一方面,pthread_key_*() 接口会假定仅使用 pthread_*()- 特别调用就能访问和修改所有声明的“与线程有关”的变量。
更改用于循环 (RR) 调度的时间片
VxWorks 提供了一种机制,用于修改循环调度任务所需的全局时间片。 QNX Neutrino 没有完全相同的调用,但它提供了一种“偶发调度”策略,可用于以精确方式控制线程的执行预算。
文件描述符 (FD) 共享
标准输入、标准输出和标准错误都与任务有关,而所有其他文件描述符都是系统范围内的。在 QNX Neutrino 中,所有文件描述符都与进程有关,因此当 VxWorks 任务映射为 QNX Neutrino 进程内的线程时会丢失这种动作。另一方面,当 VxWorks 任务映射为 QNX Neutrino 进程时,还会丢失进程内其他线程使用的共享地址空间。
先进先出 (FIFO) 顺序的唤醒
当任务等待的资源(如信号量或信息队列)可用时,VxWorks 工具能以先进先出的顺序将它们唤醒。在 QNX Neutrino 中,基本同步对象并不提供相同的唤醒机制,尽管您能使用本机 QNX Neutrino 基元模拟这类运行。
timer_connect
函数 timer_connect 位于 VxWorks timerLib(即 POSIX 计时器)内,但它实际上不是 POSIX 函数。
优先级
自 6.3.0 版开始,QNX Neutrino 就能支持 255 种不同的优先级了。对于 6.3.0版之前的版本而言,需要将 VxWorks 中 255 种优先级“压缩”为 63 种不同的优先级。只要应用程序实际需要的优先级不超过 63 个,这应该没有问题。
VxWorks 中的反转安全 (Inversion-Safe) 信号量
如果一个任务的优先级提高了,那么在它目前拥有的所有反转安全信号量被释放前,其优先级不会降低。摘自 VxWorks 文件:
“由于通过获取互斥信号量而提高的任务优先级,在该任务保留的所有互斥体被释放前会一直保持提高的优先级,因此当涉及到嵌套互斥体时,会产生无限期优先级反转的情况。”
在 QNX Neutrino 中,无论何时,与其他任何线程(被阻塞在原始线程保留的任何互斥体上)的优先级相比,指定的保留互斥体的线程都具有最高的优先级。该优先级是根据与互斥体有关的事件更新的,因此能有效防止无限期的优先级反转。
6 参考文件
QNX Neutrino 提供:
- System Architecture
- Programmer’s Guide
- Building Embedded Systems
- Library Reference
注意:上述所有文件均可从 QNX 软件系统公司的网站上获得 (http://www.qnx.com/developer/docs) .
VxWorks 提供:
- Wind River VxWorks (http://www.windriver.com/products/vxworks/)
- VxWorks/Tornado II FAQ ( http://www.xs4all.nl/~borkhuis/vxworks/vxworks.html )
- VxWorks Cookbook ( http://www.bluedonkey.org/cgi-bin/twiki/bin/view/Books/VxWorksCookBook )
关于 QNX 软件系统公司
QNX 软件系统公司是加拿大RIM公司的一员,它是创新嵌入式技术,包括中间件、开发工具和操作系统的全球主要供应商。QNX ® Neutrino ® 实时操作系统基于组件的架构、QNX Momentics ® 开发套件和 QNX Aviage ® 中间件产品系列共同提供业内最可靠和可扩展的框架,用于创建高性能嵌入式系统。包括思科、戴姆勒、通用电气、洛克希德·马丁和西门子在内的全球技术领导者都依靠 QNX 的技术生产网络路由器、医疗器械、车用远程信息处理装置、安全与国防系统、工业机器人,并满足其他任务或生命关键型应用的需要。公司总部位于加拿大渥太华,其产品行销遍布全球 100 多个国家或地区。
www.qnx.com
