1. 垫话
本文乃 Intel SDM "Chapter 8 8.2 Memory Ordering" 一节的翻译。
要点概述:
- 内存乱序的本质是因为计算机系统是分层的(分层的原因是指令执行遇到 cache 同步等开销较大的操作时,需要更多的 cycles,此时不能死等,需要把数据写入临时缓冲 — 也就是 store buffer 中),cache 之上还有 store buffer(乱序还有流水线的多发射之类的原因,这里不讨论)。
- 乱亦有道。
2. 前言[8.2]
内存序(memory ordering)指处理器发起读(load)写(store)操作时,通过系统总线提交给系统内存时的顺序。取决于具体实现,Intel 64 及 IA-32 架构支持多种内存序模型。具体来说,Intel 386 采用的是 program ordering【通常称为强序(strong ordering)】,即在任意情况下,提交到系统总线上的读写顺序与它们在指令流中的顺序一致。
为了优化指令执行的性能,Pentium 4、Intel Xeon 及 P6 family 处理器的 IA-32 架构支持不同于 strong ordering 的 processor ordering。这些 processor ordering 变种(称为内存序模型)通过诸如允许读操作先于 buffered 写操作执行而提升性能。这些变种皆旨在多核系统下保持内存一致性的情况下,提升指令执行速度。
Section 8.2.1 及 Section 8.2.2 描述 Intel 486、Pentium、Intel Core 2 Duo、Intel Atom、Intel Core Duo、Pentium 4、Intel Xeon 及 P6 family 处理器所实现的内存序。Section 8.2.3 演示 IA-32 及 Intel-64 处理器上的内存序行为。Section 8.2.4 讨论了对 string 操作 store 的特殊处理,Section 8.2.5 讨论如何使用特定指令来影响内存序行为。
3. Intel Pentium 及 Intel 486 处理器上的内存序[8.2.1]
Pentium 及 Intel 486 处理器遵循 processor-ordered 内存模型;但大多数情况下它们表现得像 strong-ordered 处理器。系统总线上的读写操作总是以其指令流顺序出现 —— 除非出现如下场景才会有 processor ordering:当所有 buffered writes 都 cache 命中时,允许 read misses 先于系统总线上的 buffered writes 执行,如此,(buffered writes)不会写入与 read misses 相同的地址(译者注:其实在此特殊情况下,即使乱序亦无妨——因为此情况下,store buffer 中的写操作,其所要写的地址都在 cache 中,而读操作其目标地址都 cache miss,证明二者并无地址上的关联性,这种情况下的乱序是“安全”的,且无需任何附加硬件逻辑的支持,亦无需软件上的修改如加内存屏障等,属于白嫖乱序,不乱白不乱。个人理解,不一定对)。
对于 I/O 操作,读写总是以 programmed order 出现。
运行在 processor-order 处理器(如 Pentium 4、Intel Xeon 及 P6 family 处理器)上的软件要想正确运行,就不能依赖 Pentium 或 Intel 486 处理器上的相对 strong ordering。相反,其在访问共享变量时,必须使用合适的 locking 或 serializing 操作(Section 8.2.5, "Strengthening or Weakening the Memory-Ordering Model")以控制处理器间的指令执行遵循 program ordering。
4. P6 及更现代处理器 families 的内存序[8.2.2]
Intel Core 2 Duo、Intel Atom、Intel Core Duo、Pentium 4 及 P6 family 处理器使用的是被定义为“write orderd with store-buffer forwarding”的 processor-ordered 内存序模型。此模型特征如下:
单处理器系统上,对于定义为 write-back cacheable 的内存区域,内存序模型遵循如下规则(注意:单处理器及多处理器系统下的内存序规则,是站在软件执行的视角来看的,“处理器”指的是逻辑处理器。具体来说,支持多核或 Intel 超线程的物理处理器,其被视作一个多处理器系统)。
- 读操作不会与其他读操作乱序(译者注:读操作之间是 program-ordered 的)。
- 写操作不会与更早的读操作乱序。
- 对内存的写操作不会与其他写操作乱序,如下场景例外:
— 通过 non-temporal move 指令(MOVNTI、MOVNTQ、MOVNTDQ、MOVNTPS 及 MOVNTPD)执行的 streaming store(写)。
— string 操作(Section 8.2.4.1)。
- 对内存的写操作不会与 CLFLUSH 指令乱序;写操作可以与 CLFLUSHOPT 指令乱序,因其只是在 flush 一个 cache line 而不是在对 cache line 进行写入。CLFLUSH 指令之间不会乱序。操作不同 cache line 的 CLFLUSHOPT 指令之间可以乱序。操作不同 cache line 的 CLFLUSHOPT 与 CLFLUSH 指令可以乱序。
- 读操作可以与更早的、目标地址不同的写操作乱序,但不可与更早的、目标地址相同的写操作乱序。
- 读写操作不可与 I/O 指令、locked 指令或 serializing 指令乱序。
- 读操作不可乱序(重排)至 LFENCE 和 MFENCE 指令之前。
- 写操作及 CLFLUSH、CLFLUSHOPT 的执行不可乱序(重排)至 LFENCE、SFENCE 与 MFENCE 指令之前。
- LFENCE 指令不可乱序(重排)至读操作之前。
- SFENCE 指令不可乱序(重排)至写操作或 CLFLUSH、CLFLUSHOPT 的执行之前。
- MFENCE 指令不可乱序(重排)至读操作、写操作或 CLFLUSH、CLFLUSHOPT 的执行之前。
多处理器系统下,遵循如下规则:
- 单个处理器个体遵循单处理器系统下的规则。
- 某个处理器写操作的顺序,与所有处理器观察到的顺序一致。
- 单个处理器的写操作与其他处理器上的写操作之间没有顺序保证。
- 内存序遵循因果律(内存序遵循传递的可见性,transitive visibility)(译者注:看后面 5.6 节就知道了)。
- 除了执行 store 的处理器之外,所有处理器看到的两个 store 操作的顺序都是一致的(译者注:不会出现某些处理器先看到 store a 再 store b,另一些处理器先看到 store b 再看到 store a)。
- locked 指令执行顺序的全局性。
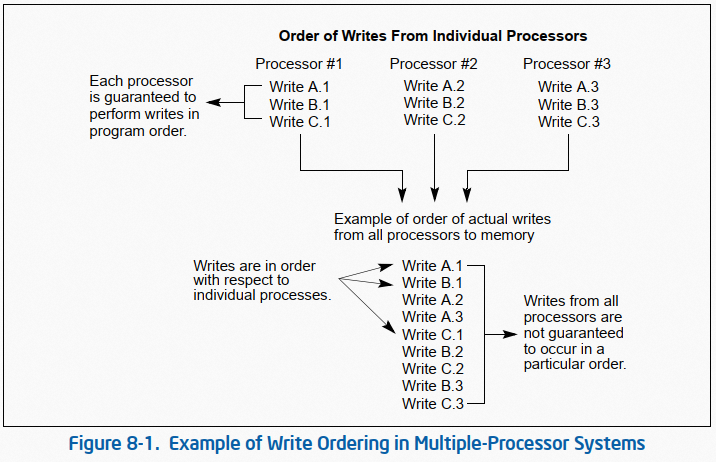
如 Figure 8-1 的例子所示,三个处理器执行对三个地址(A、B、C)的写操作。从单个处理器的视角来看,每个处理器以相同的 program order 执行写操作,但由于总线仲裁以及及其他内存访问机制(译者注:主要是 cache),这三个处理器每次对各自地址的写操作执行顺序与代码顺序可能并不相同。每次执行中写操作的顺序不同,从而导致 A、B、C 的最终值不同。
本节中所述 processor-ordering 模型实际上与 Pentium 及 Intel 486 处理器中的一致。Pentium 4、Intel Xeon 及 P6 family 处理器对此的唯一增强在于:
- 添加了对预读(speculative read)的支持,同时仍然遵守上述 ordering 原则。
- 当读操作与写操作的目标地址相同时,进行 store-buffer forwarding(译者注:store-buffer forwarding 是一种在引入 store buffer 后保持数据一致性的机制,见 5.5 节的译者注)。
- long string store 及 string move 操作的乱序 store(Section 8.2.4, "Fast-String Operation and Out-of-Order Stores")。
5. 内存序规则示例[8.2.3]
本节对 Section 8.2.2 中所述内存序规格进行案例说明,旨在帮助软件开发者理解内存序是如何影响指令结果的。
这些案例演示只限于对定义为 write-back cacheable(WB) 属性内存区域的访问(Section 8.2.3.1 描述了案例的其他限制)。案例所描述的都是软件可见的行为。即使案例所述的两条访问操作不会被乱序,逻辑处理器实际在底层也可能会对其做乱序,但从软件侧来看其无法感知底层实际上是做了乱序的。类似的,对于一条内存访问,一个逻辑处理器可能会执行多次,但从软件看来,其与只执行一次无异。
5.1 假设、术语及记号[8.2.3.1]
如上所述,这些案例只限于对定义为 write-back cacheable(WB) 属性内存区域的访问,且只涉及常规的 load、store 以及 locked read-modify-write 指令。它们不涉及如下:string 指令的乱序 store(Section 8.2.4);non-temporal 访问;处理器地址翻译流程中的读(比如 page walks);以及处理器对段及页表结构的更新(比如更新 "accessed" bits)。
Intel-64 内存序模型保证,对于如下的内存访问指令,其所涉及的多条内存操作看起来就像是单条内存访问(译者注:意思就是这些内存访问从软件看来是原子的):
- 对一个 byte 的读写指令。
- 对一个对齐到 2 byte 边界上的 word(2 bytes)的读写指令。
- 对一个对齐到 4 byte 边界上的 doubleword(4 bytes)的读写指令。
- 对一个对齐到 8 byte 边界上的 quadword(8 bytes)的读写指令。
任意 locked 指令(比如 XCHG 指令或任意其他带 LOCK 前缀的 read-modify-write 指令),无论对齐情况如何,其外部表现就是一组不可分割、不可中断的 load、store 序列(译者注:这些指令是要锁访存总线或锁 cache 的,所以是原子的)。
其他指令可能会被实现为多条内存访问。从内存序的视角来看,这些内存访问之间的顺序是无法得到保证的。一个 store 的子操作执行顺序也无法保证与一个 load 的子操作执行顺序一致(译者注:好端端的为啥要说这句话?)。
Section 8.2.3.2 到 Section 8.2.3.7 给出了 MOV 指令的例子。这类例子的底层原则适用于通用的 load、store 访问,以及其他对内存的 load、store 指令。Section 8.2.3.8 及 Section 8.2.3.9 给出了使用 XCHG 指令的例子。其底层原则适用于其他 locked read-modify-write 指令。
本节中“处理器”一词指代逻辑处理器。例子用 Intel-64 汇编语法编写,并使用如下记号:
- 以 "r" 开头的参数,比如 r1 或 r2 指代寄存器(比如 EAX)。
- 内存地址标记为 x、y、z。
- store 写为 mov [_x], val,含义是将 val 的值写入内存地址 x 处。
- load 写为 mov r, [_x],含义是将内存地址 x 处的内容加载到寄存器 r 中。
如之前所强调的,这些例子只关注软件可见的行为。当后续章节提到“两个 stores 被重排(乱序)了”,含义是“两个 store 从软件的视角来看被重排(乱序)了”。
5.2 load 或 store 指令不会在同类型指令间重排[8.2.3.2]
Intel-64 内存序模型,不允许 load 及 store 在同类型操作间的乱序(译者注:参考 2.2 节,意思就是 load 不能与 load 乱序,store 不能与 store 乱序)。这意味着,多个 load 之间是 program order 的,多个 store 之间是 program order 的。下面的例子说明之:

不被 allowed 的输出,只可能在 processor 0 对两个 store 操作进行了重排(且两个 load 出现在二者之间时),或者 processor 1 对两个 load 操作进行了重排(且两个 store 出现在二者之间时)的情况下,才会出现。
如果 r1 = 1,对 y 的 store 发生在对 y 的 load 之前。因为 Intel-64 内存序模型不允许 store 操作重排,(processor 0 上)对 x 的 store(在 r1 = 1,也就是对 y 进行了 store 的情况下)必然也发生在对 y 的 load 之前。因为 Intel-64 内存序模型不允许 load 操作重排,故而对 x 的 store 必然发生在后续对 x 的 load 之前。故 r2 必然为 1。
已知:r1 = 1,则必然 store.y 早于 y.load。根据内存序模型,store.x 必然早于 store.y,故而 store.x 早于 store.y 早于 y.load。根据内存序模型,load.y 必然早于 load.x,故而 store.x 早于 store.y 早于 y.load 早于 load.x。
5.3 store 操作不会与更早的 load 重排[8.2.3.3]
Intel-64 内存序模型保证一个处理器的一个 store 操作,不会被重排至同处理器上更早的 load 之前。下面的例子说明之:

假设 r1 = 1。
- 因为 r1 = 1,processor 1 对 x 的 store 必然先于 processor 0 对 x 的 load。
- 因为 Intel-64 内存序模型不允许在 store 操作与同处理器上更早的 load 之间重排,故而 processor 1 对 y 的 load 先于对 x 的 store。
- 同理,processor 0 对 x 的 load 先于对 y 的 store。
- 因此,processor 1 对 y 的 load 先于 processor 0 对 y 的 store,也即 r2 = 0。
5.4 load 与更早的目标地址不同的 store 之间可以被重排[8.2.3.4]
Intel-64 内存序模型允许对一个 load 与更早的目标地址不同的 store 之间做重排。但是,相同地址的 load、store 之间不可重排。下面的例子说明之:

每个处理器上,load 和 store 操作的目标地址皆不相同,故而它们之间可被重排。任意的操作交叉情况皆可能存在。其中一种可能的交叉为:两个 load 操作出现在两个 store 之前。这将导致每个 load 的返回值为 0。

Intel-64 内存序模型不允许对上述 load、store 指令序列的重排,因为 load 与 store 指令的目标地址相同。因此 r1 必然为 1。
5.5 允许处理器内部的 forwarding[8.2.3.5]
内存序模型允许两个处理器上同时发生的 store,在两个处理器看来是不同顺序的;并且,每个处理器会认为其自身的 store 会出现在另外一个处理器的 store 之前。下面的例子说明之:

内存序模型不对两个处理器上的两个 store 操作顺序做限制。这将导致 processor 0 会在看到 processor 1 的 store 之前先看到其自己的 store,processor 1 会在看到 processor 0 的 store 之前先看到其自己的 store。每个处理器是自一致的(self consistent)。这会允许 r2 = 0 且 r4 = 0。
“内存序模型不对两个处理器上的两个 store 操作顺序做限制”。这句话的本质,是因为 store buffer 的存在,store buffer 会导致处理器对某个地址内容的修改(store),对其自身是可见的,但是可能只是存在于其 store buffer 中,而未进入 cache,故而其他处理器是看不到的。
实际上,该例子的重排会引发 store-buffer forwarding。当一个 store 临时位于处理器的 store buffer 中时,其可以满足处理器自身的 load 需求,但对其他处理器的 load 是不可见(也无法保证)的。
store buffer 相当于是 cache 之上的 cache。某个处理器对某地址进行 store 时,如果此时该地址并未出现在自己的 L1 cache 中(可能是压根还没 load 进 cache,或在其他处理器的 cache 中),此时涉及到 cache 同步,处理器会先将对该地址的 store 操作推入该处理器的 store buffer 中,此时因为 cache 并未被写入,故其他处理器是看不到该地址中内容的变化的,如果此时其他处理器对该地址进行读取,其读到的仍是未修改之前的值。但如果当前处理器后续要对该地址做 load,该地址在 cache 和 store buffer 中会存在两份拷贝(cache 中是旧的值,store buffer 中是新的值),为了保证“CPU 所见的其自身指令的顺序是 program order 的“,会触发 store forwarding,也即处理器在做 load 时,不仅会参考 cache,也会参考其 store buffer。换句话说,CPU 的 store 会直接 forwarded 给其后续 load,而无须给到 cache。
5.6 store 传递的可见性[8.2.3.6]
内存序模型确保了 store 传递的可见性;有因果关系的 stores,对所有处理器看来,它们发生的顺序与因果顺序保持一致(译者注:store 传递的可见性指的是,如果两个处理器之间的 store 存在因果序,则所有处理器都可以看到这个因果序,并使得其最终结果受到此因果序的影响)。

假设 r1 = 1 且 r2 = 1。
- 因为 r1 = 1,processor 0 的 store 在 processor 1 的 load 之前。
- 因为内存序不允许 store 与更早的 load 乱序(Section 8.2.3.3),processor 1 的 load 必然在其 store 之前。因此,processor 0 的 store 因果序上先于 processor 1 的 store。
- 因为 processor 0 的 store 因果序上先于 processor 1 的 store,内存序模型确保在所有处理器看来,processor 0 的 store 先于 processor 1 的 store。
- 因为 r2 = 1,processor 1 的 store 先于 processor 2 的 load。
- 因为 Intel-64 内存序模型不允许 load 之间的乱序(Section 8.2.3.2),processor 2 的 load 之间是按序的。
- 以上逻辑确保了,processor 0 对 x 的 store 必然先于 processor 2 对 x 的 load。所以 r3 必然为 1。
5.7 其他处理器看来 store 顺序是一致的[8.2.3.7]
如 Section 8.2.3.5 所述,内存序模型允许两个处理器间的 store 从二者看来分别是不同顺序的。然而, 任意两个 store 从所有处理器(执行这些 store 的处理器除外)看来,都必须遵循相同的顺序。(译者注:意思就是涉事双方可以各自看来是不同顺序的,但是对于非涉事群体的其他所有处理器,看到的顺序相同)。下面的例子说明之:

根据 Section 8.2.3.2 中所述的原则:
- processor 2 的两个 load 不可重排。
- processor 3 的两个 load 不可重排。
- 如果 r1 = 1 且 r2 = 0,则对于 processor 2 来说,processor 0 的 store 先于 processor 1 的 store。
- 同理,r3 = 1 且 r4 = 0,表明对于 processor 3(译者注:SDM 应该是笔误了,SDM 原文这里写的是 processor 1)来说,processor 1 的 store 先于 processor 0 的 store。
因为内存序模型确保两个 store 之间的顺序,在所有处理器看来皆是相同的(执行这些 store 的处理器除外),所以是不可能出现该返回值情况的。
5.8 locked 指令执行顺序的全局性[8.2.3.8]
内存序模型保证所有处理器对所有 locked 指令的执行顺序遵循同一认知,即使目标操作数大于 8 byte 或并未天然对齐。下面的例子说明之:

processor 2 与 processor 3 必须对两条 XCHG 指令的执行顺序有相同的认知。不妨假设 processor 0 的 XCHG 先执行:
- 如果 r5 = 1,processor 1 对 y 的 XCHG 必然在 processor 3 对 y 的 load 之前。
- 因为 Intel-64 内存序模型不允许 load 之间的重排(SEction 8.2.3.2),processor 3 的 load 是按顺序发生的,因此 processor 1 的 XCHG 在 processor 3 对 x 的 load 之前。
- 因为 processor 0 对 x 的 XCHG 在 processor 1 的 XCHG 之前(假设),则其必然在 processor 3 对 x 的 load 之前。因此,r6 = 1。
5.9 load 及 store 不与 locked 指令重排[8.2.3.9]
内存序不允许 load 及 store 与更早或更后的 locked 指令乱序。本节例子只演示 locked 指令在 load 或 store 之前。读者应当知晓,如果 locked 指令在 load 或 store 指令之后,此规则亦然。
第一个例子展示 load 不会与更早的 locked 指令重排:

如 Section 8.2.3.8 所述,locked 指令的执行顺序是全局的。不妨假设 processor 0 的 XCHG 先发生。
因为 Intel-64 内存序模型不允许 processor 1 对 load 与其更早的 XCHG 重排,故 processor 0 的 XCHG 在 processor 1 的 load 之前。如此 r4 = 1。
第二个例子展示 store 不会与更早的 locked 指令重排:

假设 r2 = 1。
- 因为 r2 = 1,processor 0 对 y 的 store 先于 processor 1 对 y 的 load。
- 因为内存序模型不允许 store 与更早 locked 指令的重排,processor 0 对 x 的 XCHG 必然在其对 y 的 store 之前。因此,processor 0 对 x 的 XCHG 在 processor 1 对 y 的 load 之前。
- 因内存序模型不允许 load 之间的重排(Section 8.2.3.2),processor 1 的 load 是按顺序执行的,因此,processor 1 对 x 的 XCHG 在 processor 1 对 x 的 load 之前。因此 r3 = 1。
6. fast-string 操作与乱序 store[8.2.4]
本章节主要讲述 string 操作(rep:stosd)的内存序规则,译者觉得翻译的意义不大,直接跳过。
7. 强弱内存序模型[8.2.5]
Intel 64 及 IA-32 架构提供了多种不同的强弱内存序模型以应对不同的编程场景。这些机制包括:
- I/O 指令、locking 指令、LOCK 前缀以及 serializing 指令,强制处理器使用强内存序。
- SFENCE 指令(Pentium III 处理器引入到 IA-32 架构)和 LFENCE 以及 MFENCE 指令(Pentium 4 处理器引入),为特定类型的内存操作提供了内存序及顺序执行能力。
- memory type range 寄存器(MTRRs)可对物理内存指定强弱内存序(Section 11.11, "Memory Type Range Registers(MTRRs)"。MTRRs 在 Pentium 4、Intel Xeon 及 P6 family 处理器上可用。
- page attribute table(PAT) 可对页或一组页指定强弱内存序【Section 11.12, "Page Attribute Table(PAT)"】。PAT 在 Pentium 4、Intel Xeon 及 Pentium III 处理器上可用。
这些机制可如下使用:
memory mapped 设备及总线上的其他 I/O 设备,通常对“对其 I/O buffers 的写入”的顺序很敏感。可通过使用 I/O 指令(IN、OUT 指令)来对此类访问使用强写入顺序。在执行 I/O 指令之前,处理器会先等前面的指令执行完,且所有 buffered 写都已回写至内存。只有指令预取及页表 walks 才会在顺序上穿越 I/O 指令。I/O 指令的后续指令会一直得不到执行,直到处理器完成 I/O 指令的执行。
多处理器系统下的同步机制可能会依赖强内存序模型。程序可以使用诸如 XCHG 指令或 LOCK 前缀的 locking 指令,来确保对内存的 read-modify-write 操作是原子的。locking 操作通常像 I/O 操作一样,它们会等待所有先前的指令完成,并等待所有 buffered write 被回写至内存(Section 8.1.2, "Bus Locking")。
还可以通过 serializing 指令(Section 8.3)来做程序的同步。这些指令通常用在临界区或任务上下文边界上,以强制先前的指令都执行完毕,从而跳转至新的代码 section 或做后续的上下文切换。类似 I/O 及 locking 指令,处理器在执行 serializing 指令之前,会等待所有先前的指令完成,并等待所有 buffered write 被回写至内存。
SFENCE、LFENCE 及 MFENCE 指令提供了高性能的保证 load 及 store 内存序的方法。此三者指令的作用如下:
- SFENCE:确保指令流中所有在 SFENCE 之前的 store(写)操作不会被重排(至 SFENCE 之后),但不约束 load 操作。
- LFENCE:确保指令流中所有在 LFENCE 之前的 load(读)操作不会被重排(至 LFENCE 之后),但不约束 store 操作。
- MFENCE:确保指令流中所有在 MFENCE 之前的 store 及 load 操作不会被重排(至 MFENCE 之后)。
原注:具体来说,LFENCE 会在所有先前的指令在本地都完成后,LFENCE 才会执行,并且在 LFENCE 完成之前,所有后续指令都不会开始执行。因此,先于 LFENCE 的读内存指令,会在 LFENCE 指令完成之前从内存获取数据。一个后续跟随了内存写的 LFENCE 指令,其(LFENCE)可能会在数据写入且全局可见之前完成(译者注:LFENCE 对 store 无约束)。后续跟随了 LFENCE 的指令,在被取指时(从内存)可能先于 LFENCE 被取指,但在 LFENCE 完成之前它们都不会得到执行。
注意,相较于 CPUID 指令,SFENCE、LFENCE、MFENCE 对内存序的控制更高效。
P6 family 处理器引入的 MTRRs,用来对指定物理内存区域定义定义 cache 特性。如下两个例子展示,在 Pentium 4、Intel Xeon 及 P6 family 处理器中,如何通过 MRTTs 来建立起强弱内存序:
- 强 uncached(UC) 内存类型,强制对内存访问使用强序模型。如此,所有对 UC 内存区域的读写都会出现在总线上(译者注:意思就是不过 cache,直接给到内存控制器),且不会有乱序或预读等。此类型可用于 memory mapped I/O 设备的地址区域,以强制使用强内存序。
- 对于可以接受弱内存序的内存区域,可以选择 write back(WB) 内存类型。如此,可以做预读或 buffered 写。此类型的内存上,非跨 cache line 的原子(locked)操作会引发锁 cache(译者注:跨 cache line 的原子操作会引发 split lock,也即 bus lock,会锁访存总线,开销比锁 cache 大多了,因为 bus lock 是全局的),这些指令可以减少常规同步指令所带来的性能开销,例如 XCHG,会在整个 read-modify-write 操作期间锁总线。利用 WB 内存类型,内存访问在同一 cache line 的情况下,XCHG 指令只锁 cache 而不是 bus。
Pentium III 处理器引入的 PAT 旨在对 cache 特性进行增强,可以指定 page 或一组 page 的 cache 特性。PAT 机制会结合 MTRRs 所建立的 cache 特性,来增强 cache 特性。Table 11 展示了 PAT 与 MTRRs 的结合。
Intel 的建议是,对于运行在 Intel Core 2 Duo、Intel Atom、Intel Core Duo、Pentium 4、Intel Xeon 以及 P6 family 处理器上的程序,应当假定是 processor-ordering 或一个更弱的内存序模型。Intel Core 2 Duo、Intel Atom、Intel Core Duo、Pentium 4、Intel Xeon 以及 P6 family 处理器并未实现强内存序模型,除非使用了 UC 内存类型。尽管 Pentium 4、IntelXeon 及 P6 family 处理器支持 processor ordering,Intel 并不保证未来的处理器也支持此模式。为实现软件对未来处理器的可移植性,建议 OS 提供基于 I/O locking 和/或 serializing 指令实现的临界区、资源控制及 API,以保证多处理器系统下对共享内存区域的同步访问。同时,软件也不应当依赖 processor ordering。
