1 垫话
x86架构相关的内存序及内存屏障知识,参阅《Intel SDM之Memory Ordering》。
本文为Arm Developer《Learn the architecture-Memory Systems,Ordering,and Barriers》的翻译(https://developer.arm.com/documentation/102336/0100?lang=en)。
本文非常之好,回答了我对于啥是“观察者”、啥是“Shareability domain”以及啥是“访问完成”的定义性困惑。那些讲内存屏障但不先讲清楚以上这些基础概念的文章都拉黑吧,因为作者只是在机械地背诵,而不是真正的理解了;或者作者压根就没思考过底层细节,因为但凡思考过,这些基础概念必然是跳不过去的。
相对而言,Intel spec行文要严谨、易读一些,Arm spec略显诘诎聱牙(当然本文严格意义上不算是spec,只是一篇guide),可能是语言表达习惯问题。
2 综述
本文介绍Arm v8-A架构的内存序模型,并介绍Arm的各种内存屏障。本文还会指出一些需要明确内存保序的场景,并指明如何使用内存屏障来让程序运行正确。
本文档适用于底层代码(比如boot代码或驱动)开发者,以及共享内存的多线程应用程序开发者。
3 前置知识
译者:第3章内容属于《Learn the architecture - AArch64 memory model》一文,是本文所要探讨内容的前导知识。
3.1 Memory types
系统中所有未标记为faulting的地址都会被赋予一个memory type。memory type用来从high level角度描述处理器与地址区域的交互行为。Arm v8-A和Arm v9-A 架构下有两种memory types:Normal memory和Device memory。
注意:Arm v6和Arm v7下还有第三种memory type:Strongly Ordered。在Arm v8下,该类型对应Device-nGnRnE。
3.2 Normal memory
Normal memory用于行为看起来像是一个memory的东东,包括RAM、Flash或ROM。代码只能位于被标记为Normal的位置。
Normal是系统中最常见的memory type,如下图:
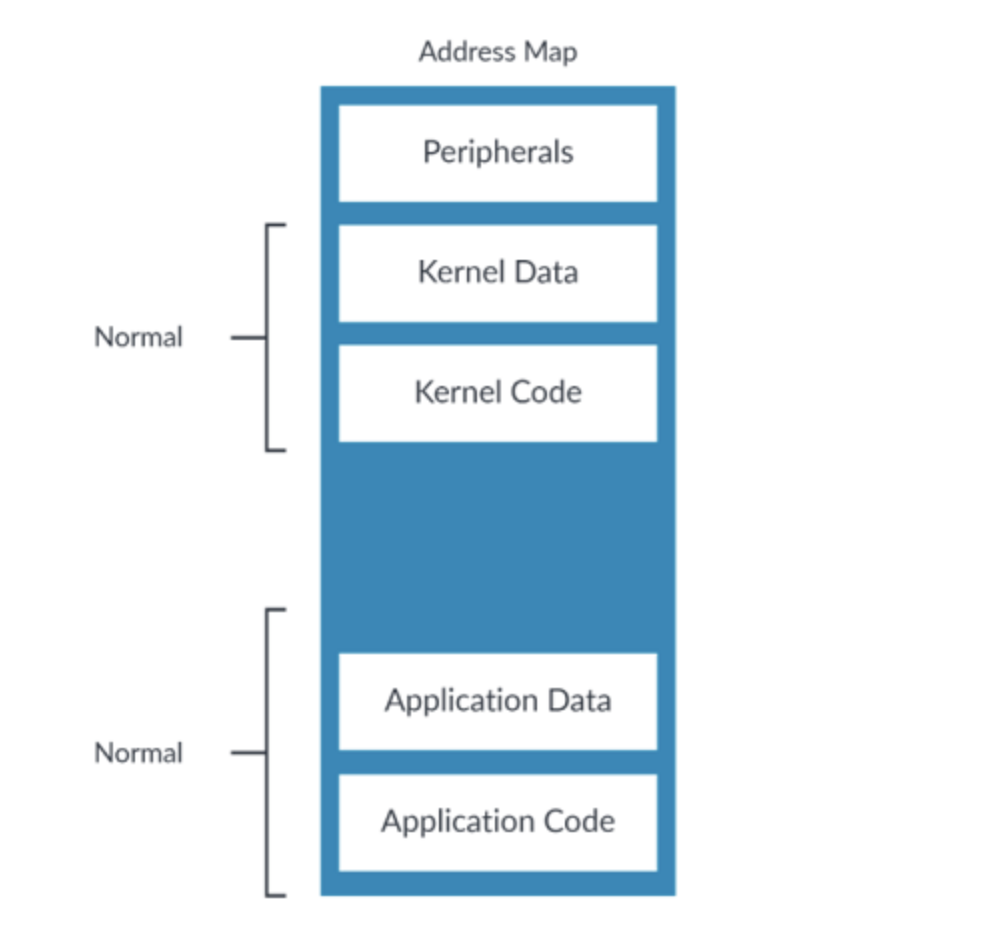
图1:normal type
3.2.1 内存访问序
通常情况下,处理器会按照程序所指定的顺序运行指令。一个指令会按照程序所指定的次数运行,并且每次只运行一个指令,这称为"Simple Sequential Execution(SSE)"模型。大多数现代处理器都似乎遵循此模型,但实际上底层会进行一系列优化,以帮助提升性能。
对一个被标记为Normal的内存地址进行访问是不会产生直接副作用的(direct side-effects)。也就是说,对此内存地址进行读取会返回数据,且不会引起数据发生变化,或直接触发一些其他的行为。正因为如此,处理器可以对“对Normal类型内存地址的访问”进行访问合并、投机读(译者:speculative access,我觉得译为“预读”问题也不是很大)或是乱序读。
3.3 Device memory
Device memory type是用来描述外设的。外设寄存器通常称为Memory-Mapped I/O(MMIO)。下图是一个示例地址映射下被标记为Device的内存区域:
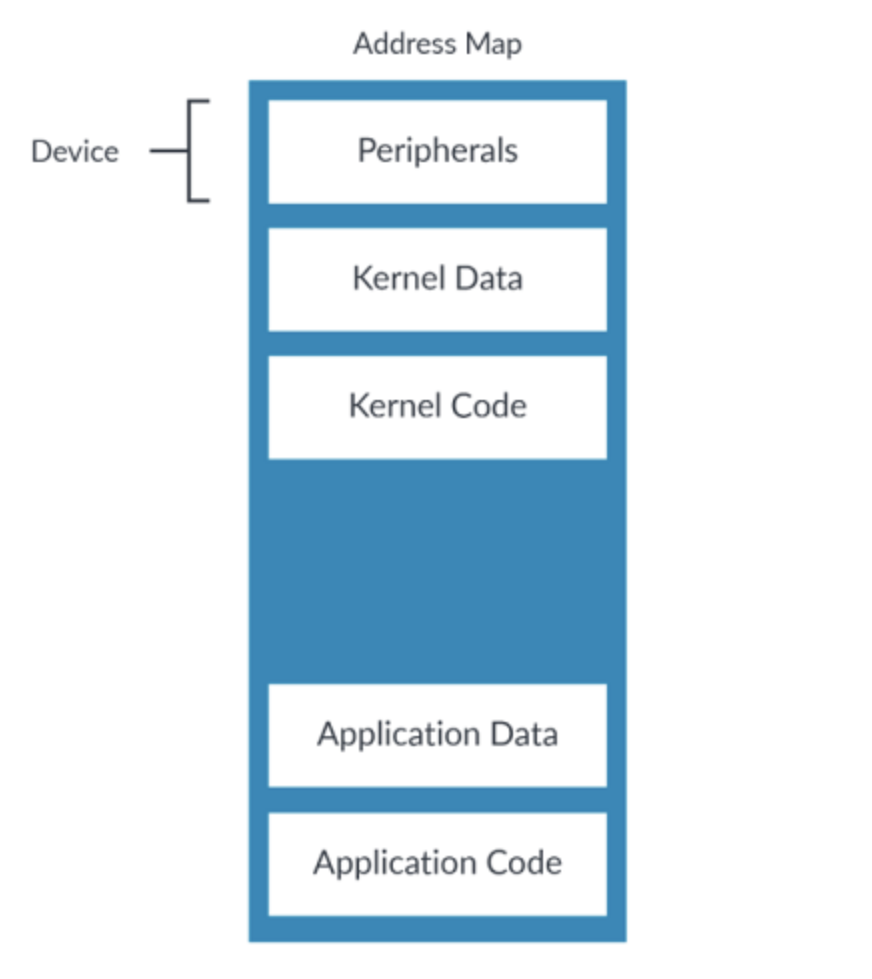
图2:memory mapped device type
对Normal type内存的访问是没有副作用的,而对Device type内存的访问则相反。Device memory type用于有访问副作用的内存地址。
举例来说,对一个FIFO的访问通常会导致其移动到下一个数据片段。这意味着对FIFO的访问次数其影响至关重要,因此处理器必须严格遵循程序的定义。
Device区域不是cacheable的,这是因为大概率你应该是不会想对设备访问进行缓存的。
Device type的内存区域上不允许做数据的投机读。处理器只能访问architecturally accessed的内存,所谓的architecturally accessed,意思就是指令在执行时所明确要访问的内存。
这里值得重点注解一下,本文行文中有多种对内存访问的定语修饰,比如architecturally accesses、explicit data accesses,其意思都差不多,指的是一条指令中明确的对内存所进行的访问,典型如“LDR X0,[X1]、STR X0,[X1]”这种。那难道还有非architecturally accesses或implicit data accesses吗?
有的,比如一次load背后可能会涉及到页表查询,页表查询也是一种内存访问,但其并不是由指令显式所指定的,页表查询这类所引发的内存访问,不是architecturally accesses或explicit data accesses。
不应该把指令放在Device区域。推荐的做法是总是将Device区域标记为不可执行,否则处理器可能会从该区域做指令预取,进而会在FIFOs这类“读敏感”设备上搞出问题。
这里有一个容易被忽略的微妙区别。将一个区域标记为Device,只会阻止对其进行数据的投机读。将一个区域标记为non-executable,会阻止指令预取。这意味着,如果要阻止对一个区域的一切投机访问,需要将其同时标记为Device和non-executable。
3.3.1 Device type的sub-types(子类型)
Device type有四种子类型,分别对应不同的限制级别。以下是最宽松的几种子类型:
- Device-GRE
- Device-nGRE
- Device-nGnRE
该子类型是最严格的:
- Device-nGnRnE
Device后面的字母表达的是属性的组合:
(1)Gathering(G,nG)。表示访问可以被合并(G)或不可以被合并(nG)。意思是可能会将对同一地址的多个访问合并为一个访问,或将多个小的访问合并为一个大的访问。
(2)Re-ordering(R,nR)。表示对同一外设的访问可以被乱序(R)或不可以被乱序(nR)
(译者:我觉得翻译成“乱序”或“重排”都行)。当允许乱序时,其乱序规则与Normal type一致。
(3)Early Write Acknowledgement(E,nE)。此属性决定一个 write 操作何时可以被认为是“已完成”的。如果允许Early Write Acknowledge(E)
(译者:early可以简单理解为“提前”,在事实生效之前,具体讨论见“9. 一次访问何时被认为是'已完成'”),则一旦一个write操作对其他观察者可见,即使该访问并未真正到达其目的地,该访问依然会被视为“已完成”。
举例来说,一个write操作只需要到达interconnect中的write buffer,即可对其他Processing Elements(PEs,译者:就是一个处理器啦)可见。如果不允许Early Acknowledge(nE),则写操作必须到达其目的地。
下面是两个例子:
- Device-GRE。此允许gathering、re-ordering以及early write acknowledgement。
- Device-nGnRnE。不允许gathering、re-ordering以及early write acknowledgement。
上面已经讲过re-ordering的工作原理,但尚未涉及gathering或early write acknowledgement。gathering可以将对同一地址的多个内存访问合并为一个bus transaction,如此实现对访问的优化。
early write acknowledgement表示是否允许内存系统在一个buffer达到core和外设之间的bus上时,就发出write acknowledgement,这样即使外设尚未收到此write操作,其他PEs也可以观测到此write操作。
注意:Normal Non-cacheable以及Device-GRE看起来是一回事,实则不是。Normal Non-cacheable允许数据的投机访问,而Device-GRE不然。
3.3.2 处理器真的会在不同type上有不同行为?
memory type描述了一个地址的可允许行为(译者:“行为”指合并、乱序、投机读等)。咱们只关注Device type,下图展示了所允许的行为:
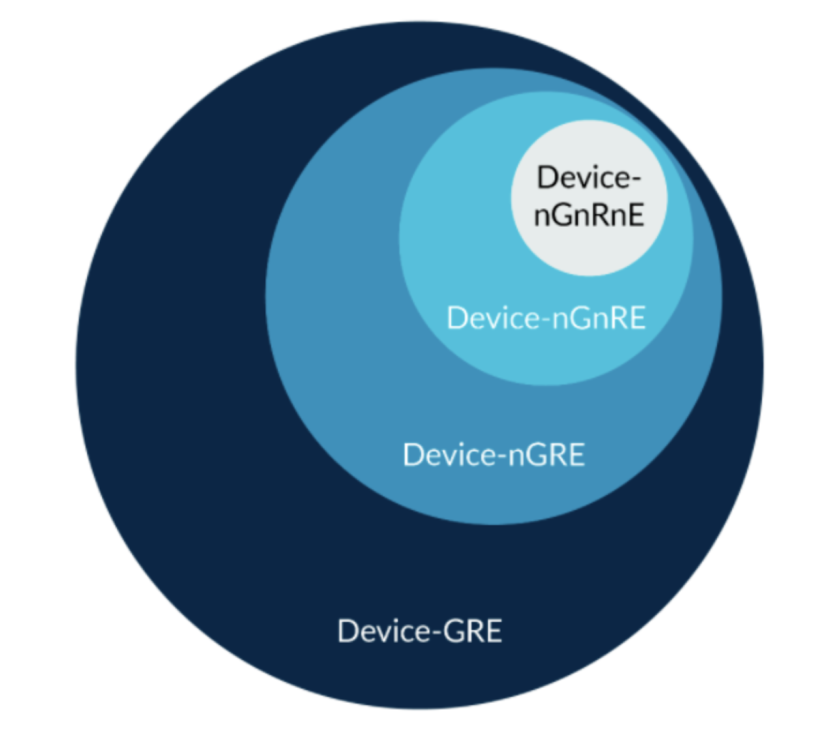
图3:device type
可以看到,Device-nGnRnE是最严格的子类型,可允许的行为是最少的。Device-GRE是最不严格的,因此其所允许的行为也是最多的。
值得注意的是,Device-nGnRnE所允许的行为也是Device-GRE所允许的。举例来说,对Device-GRE内存并不要求一定要使用gathering——它只是允许gathering。因此处理器是可以将Device-GRE当作Device-nGnRnE来对待的。
这个例子很极端,在Arm Cortex-A处理器上似乎并不会这样。然而,处理器通常不会在所有type以及sub-type间做区别对待(译者:理解为处理器的设计也不可能做的如spec描述的那么细),比如对Device-GRE和Device-nGRE用同一种方式处理。这只在type或sub-type总是更严格时会这样。
有些interconnects并不能完全支持DEvice-nGnRnE的要求。
举例来说,一个对PCIe Base Register(BAR)空间的Device-nGnRnE write,一旦在其到达PCIe topology之后就立刻变成一个posted write(一个无需“写完成”response的write)。
此场景下,该write访问只会有Device-nGnRE属性,因为目标endpoint无法提供write的response(译者注:目的端都压根不能回复response了,就不能强行要求nE),而是由某些中间组件(比如PCIe Root Port)来提供。
然而,对PCIe配置空间的Device-nGnRnE write是一个non-posted write(需要“写完成”response的write),因此这些类型访问的Device-nGnRnE需求是可以被满足的。
4 内存序(memory ordering)
Arm v8-A是个弱内存序体系结构,其所支持的内存访问,不会强加任何需要被发起或观察的依赖关系(译者:This architecture permits memory accesses which impose no dependencies to be issued or observe),并且会以与program order所指定顺序完全不同的顺序完成。
这种弱内存序的内存行为,只会在以下场景下被允许:
- 所指向内存是Normal、Device-nGRE或DeviceGRE。
- 跨越一个外设的Device-nR访问。
内存乱序可以让处理器运行地更快,如下图所示:
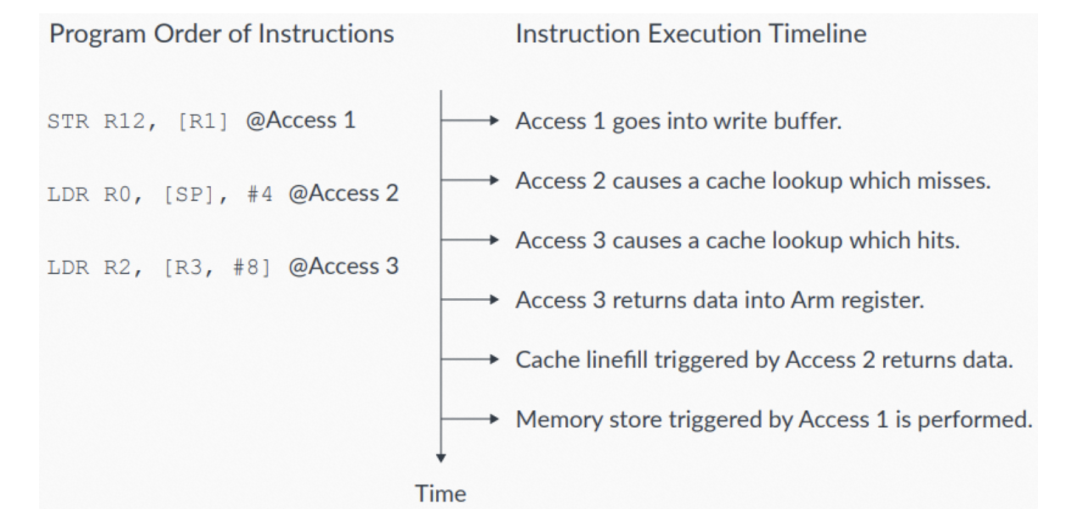
图4:内存序示例
图4中,有三条program order指令:
- 第一条指令,Access 1,对外部内存的write进入write buffer。此指令后面是两条program order的read。
- 第一个read,Access 2,未命中cache。
- 第二个read,Access 3,命中cache。
这两个read都可以在Access1的write buffer完成write之前完成。支持Hit-Under-Miss的缓存系统,支持命中cache的load操作(比如Access3),可以在程序中更早的未命中cache的load操作(比如Access2)之前完成。
(译者:这很make sense,命中cache的load与未命中 cache的load,二者之间并无数据上的冲突,乱序是安全的,有点类似《Intel SDM之Memory Ordering》"3. Intel Pentium及Intel 486处理器上的内存序[8.2.1]"中的乱序)。
4.1 乱序的限制
在Normal、Device-nGRE或Device GRE内存上的乱序是可能的。考虑下面的代码序列:
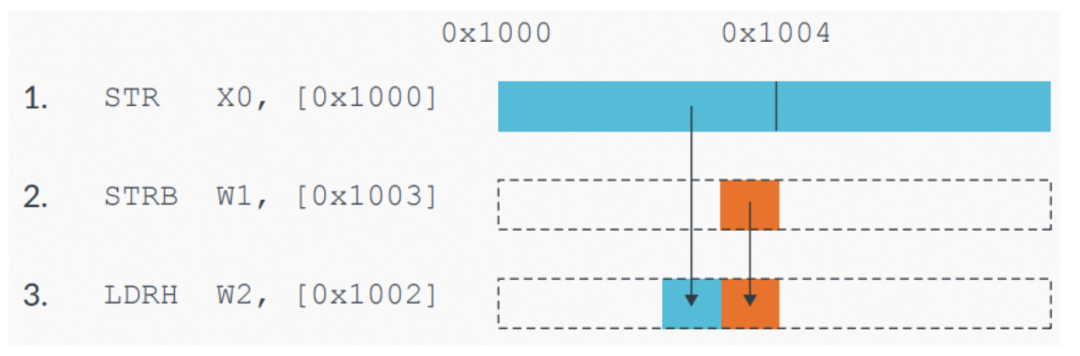
图5:示例内存乱序限制的代码序列
如果处理器对这些访问进行乱序,可能会导致内存中出现一个错误值,而这是不允许的。
对同一内存区域的访问(译者:比如本例子中的三条指令,是对0x1000-0x1003这一相同区域进行访问),必须在它们之间保序。处理器必须检测“写后读(read-after-write)”冒险(hazard,译者:“数据冒险”,这是一个标准翻译),并要保证访问之间的顺序必须是正确的,否则会出现非预期结果。
但这并不意味本示例中的访问是无法被优化的。处理器可以将两个store合并在一起,最终向内存系统呈现为一个合并后的store。处理器还要能检测load操作的目标内存是store指令所写目标内存的情况,也就是说,处理器可以直接返回新的值而无需重新从内存中读取(译者:类似store buffer forwarding,参阅《Intel SDM之Memory Ordering》“5.5允许处理器内部的forwarding[8.2.3.5]”)。
注意:上面的代码序列是刻意构造以展示数据冒险的。具体实践中,数据冒险可能不会这么显而易见。
再举一个因为存在地址依赖(Address Dependencies)而必须按序执行的例子。地址依赖的一个具体场景是,一个load或store使用前面的一个load的结果作为地址。下面是例子:
LDR X0, [X1]
STR X2, [X0] ; Result of previous load is the address in this store.
下面是另一个例子:
LDR X0, [X1]
STR X2, [X5, X0] ; Result of previous load is used to calculate the address.
如果两个内存访问之间存在地址依赖,则处理器会按其program order执行。
该规则并不适用于控制依赖(control dependencies),也就是前一个load的结果是用来做判断的(译者:而不是用来访问的,比如示例代码中的CBZ)。比如:
LDR X0, [X1]
CBZ X0, somewhere_else
LDR X2, [X5] ; The control dependency on X0 does not guarantee ordering.
有些情况下,需要对Normal内存的访问之间或对Normal和Device内存的访问之间进行保序,这时候就需要使用屏障指令。
5 内存屏障(memory barriers)
内存屏障是一类指令的总称,该类指令可以显式指定某种形式的保序、同步或对内存访问的限制。
Arm v8体系结构所支持的内存屏障提供了很多功能,包括:
- load和store指令间的保序。
- load和store指令的完成(completion)。
- 上下文(context)同步。
- 对投机访问的限制。
有些场景下弱内存序的体系结构乱序行为是个搅屎棍,其会导致非预期结果。本文介绍体系结构所支持的各种类型的内存屏障,并指出一些需要明确保序的典型场景,同时指出如何通过内存屏障来得到预期结果。
6 啥是观察者(Observer)?
Arm v8-A Architecture Reference Manual使用“观察者”(译者:因为observe既是Observer的词根,也会当动词来用,为行文清晰起见,“观察者”后续一律不翻译而是直接用Observer)这一术语来描述内存屏障所能产生的影响。
一个Observer,指的是一个Processor Element(PE),或系统中的其他部件,这些部件可以从内存中read,或向内存中write,典型如外设。Observers可以对内存访问进行观察。内存屏障可以指定哪些observers可以在何时观察到这些内存访问。
译者:这里值得再次重点注解一下,observe(观察)一词我个人觉得其实是比较头疼的,叫“perceive(感知)”可能会更容易让人理解。所谓的“观察到”一个内存被更新,指的就是对于这个Observer来说,其“感知到”该内存被更新了,也就是在该Observer对此内存发起read或write时,它已明确知晓此内存处最新的值。原文中还用了“visible(可见)”一词,所谓“visible”,就是“可被观察到的”。
一个内存write在到达内存系统中的某个点时,将变的“可见(visible)”。当write可见时,其对于内存屏障指令所指定Shareability domain上的所有Observers来说是一致的(译者:就是大家看到的值一定是相同的)。
假设一个PE对一个内存地址进行write,如果其他PE在读相同地址时可以观察到更新后的值,则此write操作是“可被观察到的”。举例来说,如果内存是Normal cacheable的,则write操作会在到达Shareability domain的coherent data caches(译者:这么多定语,简单理解为cache即可)时,成为“可被观察到的”。
Arm v8-A内存模型被描述为Other-multi-copy atomic。在一个Other-multi-copy atomic系统中,一个Observer对某地址的write,如果可以被不同的Observer所观察到,则对该地址进行访问的所有其他Observers,它们所观察到的结果应该是一致的。但是,一个Observer在它的writes对系统中其他Observers可见之前,Observer是可以观察到其自己的writes的(译者:在store buffer里面)。
工程实践中,一个描述为Other-multi-copy atomic的内存模型,会允许PEs实现local store buffers,这些store buffers并不会对系统中的其他Observers一致(译者注:意思是PE自己能看到store buffer中的内容,但其他PE看不到),但会被用来做依赖关系的冒险检查。Store Buffers(STBs)微架构机制用来将一个PE的指令执行流水线与Load/Store Unit(LSU)解耦。
7 数据内存屏障(data memory barriers)
Data Memory Barrier(DMB)用于防止指定的explicit数据访问会跨越屏障指令乱序。program order上在DMB之前的所有explicit数据load或store指令,会在program order上该DMB之后的数据访问之前被指定Shareability domain中的所有Observers观察到。
DMB指令接受一个参数,该参数指明所需保序的explicit访问所属的types,以及Shareability domain中保序所需面向的Observers。相关讨论在下文"10.内存屏障范围的限制"。
以下代码展示了在弱内存序模型下可能的乱序。X1和X3地址处的内存初始为0x0:
STR #1, [X1]
STR #1, [X3] ; Might be observed before the previous STR.
该例子中,X3地址处内存的更新和被观察到,可以发生在X1地址之前。现在假设另一个Observer以相同顺序读取两个相同的内存地址,下表展示了内存系统可能会返回的观察值组合:
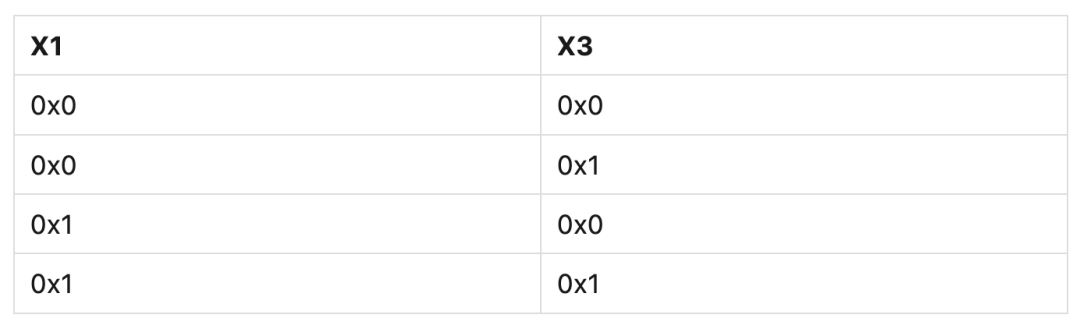
表1
下面的例子使用DMB指令来强制内存保序。X1和X3地址处的内存初始为0x0:
STR #1, [X1]
DMB
STR #1, [X3] ; Cannot observe this STR without first observing the previous STR.
该例子中,X3地址处内存如果被观察到已更新,则X1地址处内存必然也被观察到已更新。现在假设另一个Observer以相同顺序读取两个相同的内存地址,下表展示了内存系统可能会返回的观察值组合:
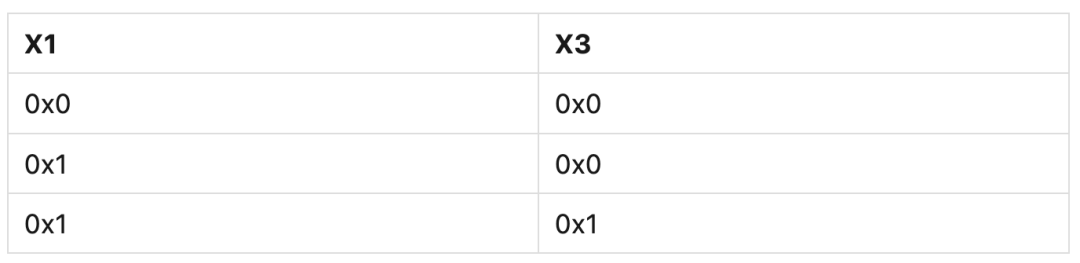
表2
下面是关于DMB的更多信息:
- 使用一个DMB可以在访问之间创建一个顺序。Arm v8-A Architecture Reference Manual将此顺序称为Barrier-ordered-before。
- 对于DMB来说,data cache maintenance operations(译者:就是data invalidation之类的那些指令)被视作explicit数据访问指令,其遵循DMB的内存序限制。
注意:如果要用DMB指令来对cache maintenance指令进行保序,必须指定一个同时包含loads和stores的参数。
- DMB无法保证访问出现的时机。DMB保证当访问真正发生时,会采用屏障和其参数所定义的顺序限制。DMB允许PE在explicit数据等待完成期间继续执行。
- DMB不会阻止后续explicit数据read操作被投机执行。如果投机执行了一个read,core必须丢弃寄存器中的投机数据(译者:这有点类似分支预测失败了要flush流水线。这里表达的是,DMB只会保证数据被“被观察到”时的顺序,而不保证微架构层面的执行顺序,比如DMB后面的数据可能会被投机读之类的)。在前面的所有explicit数据访问被观察到之后,core必须重新执行这个 load(译者:因为投机错了呗)。
8 内存同步屏障(data synchronization barriers)
DSB内存屏障用于确保在此DSB之前的内存访问,必须在DSB指令执行完成之前完成。正因如此,其是一个比DMB约束更强的内存屏障。由指定参数的DMB所带来的保序,相同参数的DSB也可以做到。
一个PE所执行的DSB会在如下情况执行完成:
- program order上,在DSB之前的所有指定访问类型的explicit内存访问都已完成,指定Shareability domain中的其他Observers皆可观察到。
- 如果DSB中所指定的参数是reads和writes,则由PE在DSB之前发起的所有cache maintenance指令以及所有TLB maintenance指令都已完成(对于指定Shareability domain来说)。
同样的,program order上DSB指令之后的指令,都无法在DSB指令完成之前,对系统状态产生任何更改,或是发挥其任意部分功能(译者:原文比较头疼,其实就是想表达“压根没有一丁点被执行到的可能”)。DSB无法阻止对指令的预取和解码。
下面的代码展示DSB所带来的保序效果:
STR X0, [X1] ; Must complete before the DSB can retire.
DSB
ADD X1, X2, X3 ; Must NOT be executed before the first STR completes.
STR X4, [X5] ; Must NOT be executed until the first STR completes.
上面代码中的DSB,可以确保第二条STR以及ADD指令不会在第一个STR以及DSB执行完成之前执行。
9 一次访问何时被认为是“已完成”?
上一节中提到,DSB可以强制之前的由DSB参数所指定的内存访问先完成(译者:原文对DSB指令使用的描述动词是"retire")。那么一次内存访问到底何时才被视为“已完成”?
read的完成解释起来要比write的完成要简单一些。这是因为,一次read的完成点是所读数据被返回到PE的architectural通用寄存器中。
一次write的完成要更复杂。对于一次对Device内存的write来说,write的完成点取决于此Device memory type所指定的Early-write acknowledgement属性。如果内存系统支持Early-write acknowledgement,则DSB指令可以在write到达end外设之前完成(译者:原文使用的动词是retire)。对于一个Device-nGnRnE的内存write,只能在内存系统收到end外设的write response时才算完成。
下面的例子中,DSB指令会一直阻塞执行,直到对Device-nGnRnE内存的STR操作从end外设收到对指定内存地址的write response:
STR X0, [Device-nGnRnE] ; Must receive a write response from the end-peripheral DSB SY
10 内存屏障范围的限制
DMB和DSB内存屏障指令都需要一个参数,来指明内存屏障所要保序的内存访问的type以及指令所作用的Shareability domain。此参数所指定的范围,决定了屏障指令的保序行为所影响的Observers。
该对内存屏障影响范围进行指定的能力,在内存屏障效果优化时会很有用。有些场景下,一个屏障的全量保序约束会太过严格(译者:开销会比较大)。如果限制一个屏障所能影响的内存访问以及Observers范围,会带来微架构层面的优化,进而减少内存屏障对性能的影响。
注意:Arm v8-A AArch64体系结构要求在使用DSB或DMB时必须显式定义参数。此约束与之前的版本不同,之前的版本在不指定明确参数的情况下会使用默认选项SY。
下表是DSB和DMB的合法参数:

表3
举例来说,DMB ISHST只会影响explicit store指令的顺序,屏障两侧的loads顺序不受影响。DMB也只会在执行该指令的PE所在的Inner Shareable domain的Observers间进行保序。
考虑下面的例子:
PE0
LDR x0, [X4] ; Can be observed out-of-order STR #1, [X1]
DMB ISHST
STR #1, [X3]
如果PE0和PE1不属于同一Shareable domain,那么架构上是允许PE1在观察到X1地址处内存被更新之前先观察到X3地址处内存被更新的。另外,所有PEs(包括 PE0)会观察到X4的load相对X1和X3的write是乱序的。
这种对保序范围的缩小,会减少在Observers之间保序时的系统开销。
11 各种观察者
以下在体系结构中被视为独立的Observers:
- core的指令接口,通常称为Instruction Fetch Unit(IFU)。
- 数据接口,通常称为Load Store Unit(LSU)。
- MMU页表遍历单元。
如“6.啥是观察者(Observer)”一节,一个Observer是可以发起内存访问的部件,比如,MMU会在遍历页表时发起read。
AArch64不会对不同Observer所发起的访问进行保序,即使访问间存在地址依赖。举例来说,以下指令序列可能会乱序,即使它们之间存在依赖:
DC CVAU, X0 ; Operations are executed in any order
IC IVAU, X0 ; despite address dependency.
如果这些指令被乱序,指令cache可能会被填充进数据cache中的过期数据。为解决此问题,需要一个内存屏障。例子如下:
DC CVAU, X0 ; Operations are executed in any order
DSB ISH
IC IVAU, X0 ; despite address dependency.
该例子中,数据cache clean(DC CVAU)会在指令cache invalidate(IC IVAU)执行之前完成。DC CVAU保证了在执行invalidate之前,新的数据总是对指令cache可见。
这里需要DSB是因为DMB只会影响数据访问,也就是只能影响到数据cache maintenance指令,而无法影响到cache invalidate指令。
12 load-acquire与store-release指令
Arm v8-A AArch64提供了一组面向loads的带有Acquire语义的指令,以及面向stores的带有Release语义的指令。这些指令支持了Release Consistency sequentially consistent(RCsc)模型。
这些新的load和store指令包含了隐晦的屏障语义,有点类似单向屏障。这些指令相对DMB或DSB来说保序语义更弱,因为它们会影响内存屏障指令两侧的指定explicit 内存访问的顺序。Load-Acquire和Store-Release指令所引入的弱保序能力支持在微架构层面的优化,从而降低显式内存屏障所带来的性能影响。如果内存序可以通过Load-Acquire或Store-Release完成,则更推荐使用这些指令而不是DMB。
Shareability domain定义了这些指令保序所能影响的Observers范围。Load-Acquire和Store-Release所影响的Shareability domain,就是该指令所访问的地址的Shareability domain(译者:load-acquire和store-release没法像DMB、DSB那样通过参数指定所要影响的Shareability domain,只能是其访问的地址属于什么Shareability domain就是哪个Shareability domain)。
举个例子,如果PE0和PE1不在同一个Inner Shareable domain中,那么下面的代码中,如果X3是Inner Shareable的,则架构上会允许PE1在观察到X1地址处内存被更新之前观察到X3地址处内存被更新:
PE0
STR #1, [X1]
STLR #1, [X3]
下面是关于Load-Acquire和Store-Release指令的一些更多信息:
- 对于Load-Acquire、Load-AcquirePC以及Store-Release指令,所传入的数据地址必须对齐到所要访问的数据长度,否则访问会触发Alignment fault。
- 对于Load-Acquire Exclusive Pair以及Store-Release Exclusive Pair,所传入的数据地址必须对齐到所要load的数据长度的两倍。否则访问会触发Alignment fault。
如下面代码所示:
LDAXP x0, x1, [0x08] ; Alignment fault
LDAXP x0, x1 [0x10]
- Load-Acquire和Store-Release还有各自的独家变体。
12.1 Load-Acquire
Load-Acquire LDAR指令的保序规则如下:
- 所有LDAR之后的explicit内存访问,会在LDAR之后被观察到。
- 所有LDAR之前的explicit内存访问不受影响,可以无视LDAR而乱序。
下图展示了具体的保序规则:
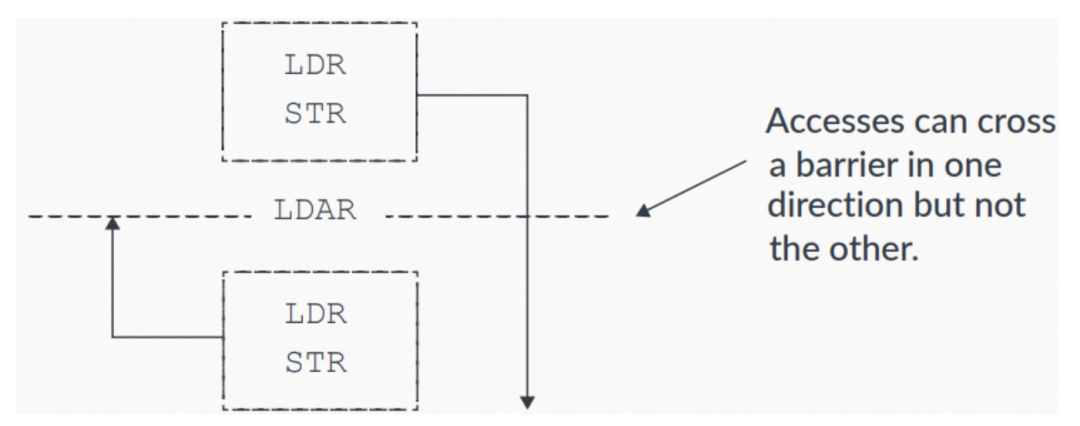
图6:LDAR保序规则
12.2 Store-Release
Store-Release STLR指令的保序规则如下:
- 所有STLR之前的explicit内存访问,会在STLR之前被观察到。
- 所有STLR之后的explicit内存访问不受影响,可以无视STLR而乱序。
下图展示了具体的保序规则:
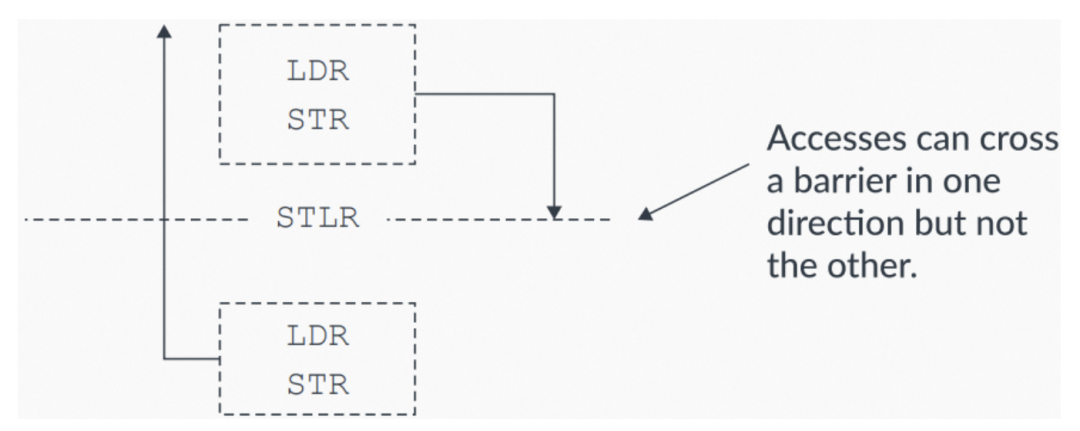
图7:STLR保序规则
下面的示例代码,展示如何通过STLR来保序。X1和X3地址处的内存初始为0x0:
STR #1, [X1]
STLR #1, [X3] ; Cannot observe this STLR without observing the previous STR.
该示例中,如果X3地址处的内存被观察到被更新了,则X1必然也被观察到被更新了。现在假设另一个Observer以相同顺序读取两个相同的内存地址,下表展示了内存系统可能会返回的观察值组合:
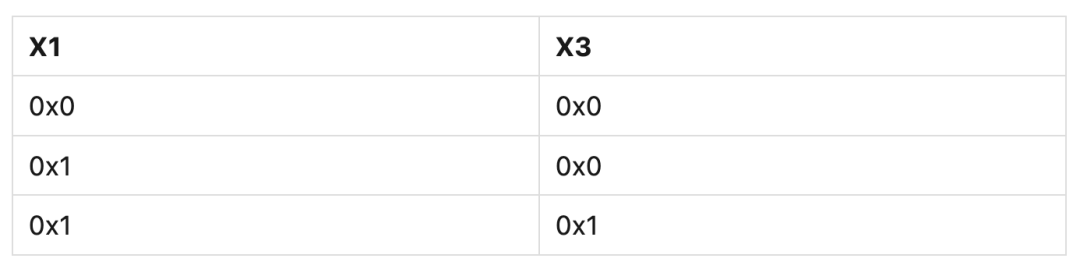
表4
12.3 Load-Acquire和Store-Release pairs
Load-Acquire和Store-Release指令可以作为一个pair组合来对代码临界区进行保护。这些指令的组合使用,可以确保代码临界区内的访问不会被乱序到临界区之外。代码临界区之外的访问(译者:这里原文应该是笔误了,原文是accesses inside the critical code section)不受影响,可以被乱序,如下图所示:
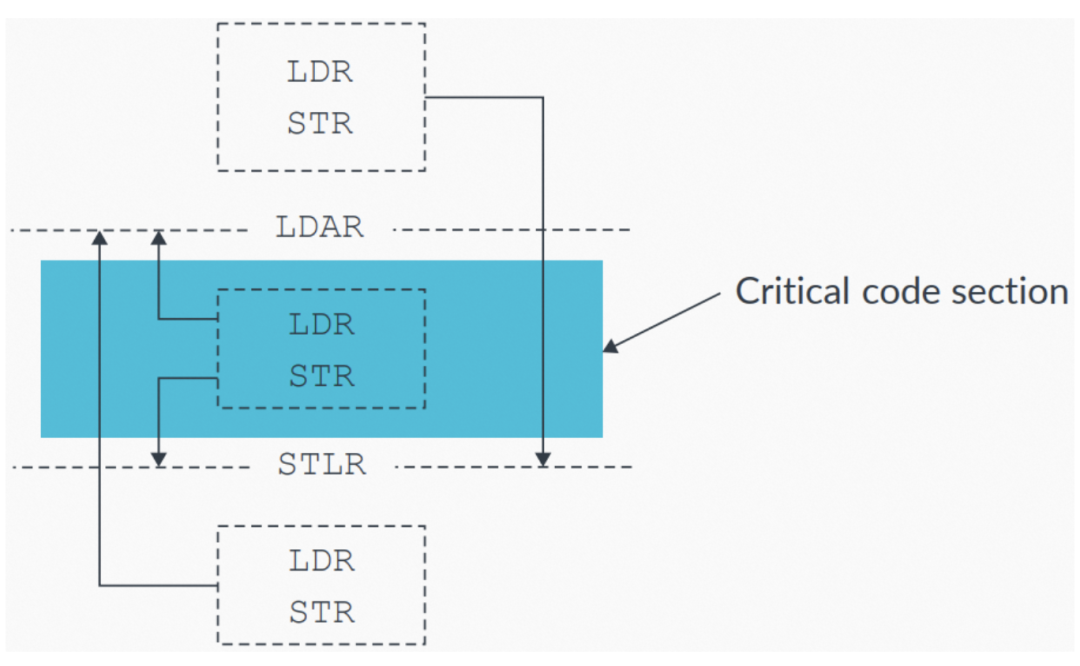
图8:使用 LDAR-STLR pair保护一个代码临界区
12.4 sequentially consistent
acquire/release操作使用sequentially consistent模型。意思是,当一个Load-Acquire在program order上位于一个Store-Release之后时,则由Store-Release指令所发起的内存访问,将先于Load-Acquire指令所发起的内存访问被观察到。下图展示了这种保序约束:
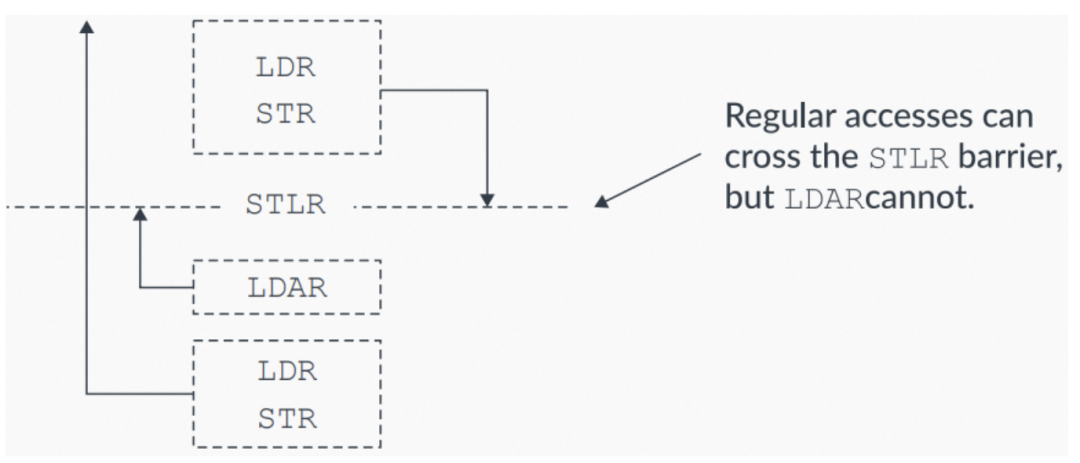
图9:sequentially consistent保序要求
12.5 Load-AcquirePC
Arm v8.3-A还提供了Load-AcquirePC指令。Load-AcquirePC和Store-Release的组合使用,可以支持更弱的Release Consistency processor consistent(RCpc)模型,如下图所示:
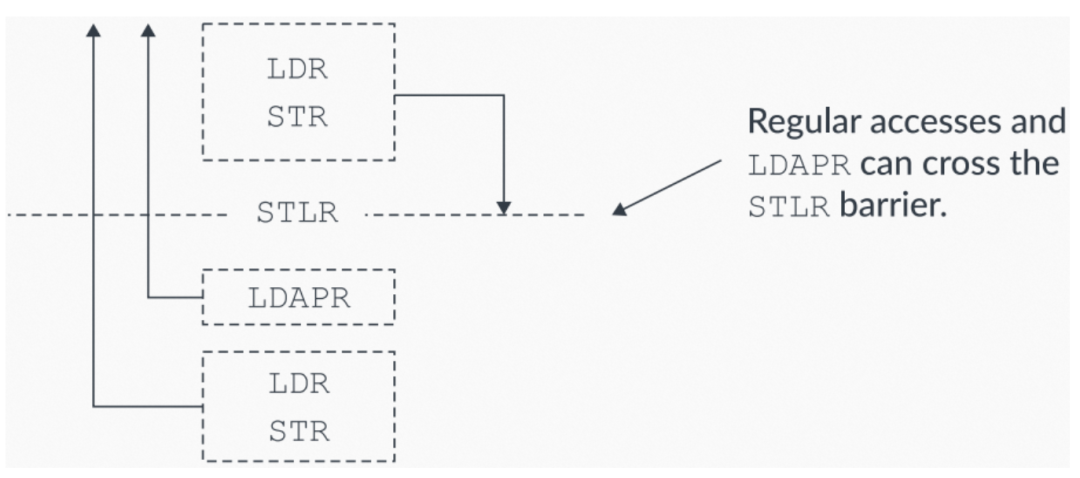
图10:Load-AcquirePC指令
通过这些新的Load-AcquirePC指令,无需再遵守Load-Acquires必须在Store-Release之后被观察到的约束(译者:对比图9看)。
12.6 Limited Ordering Regions
Arm v8.1-A添加了对Limited Ordering Regions(LORegions)(译者:受限的保序区域)的支持。LORegions支持大型系统(译者:此处所谓的“大型系统”,应该指的是内存规模比较大的系统,比如多NUMA系统)通过特殊的Load-Acquire(LDLAR)和Store-Release(STLLR)指令,来为“对指定物理地址(Physical Address,PA)映射的内存访问”间进行保序。
LORegions可以避免在等待一个内存访问(针对内存映射中的任意地址,并对发起访问的PE所属的Shareability domain中的所有Observers可观察)时的大量性能开销。
该场景(译者:指的是引入性能开销的场景)可能由现有的Load-Acquire和Store-Release指令引入(译者:这里的意思是说,原先的Load-Acquire、Store-Release指令会导致有些访问必须在屏障之前完成,导致CPU一直等待直至访问完成而引入性能开销)。此特性只在软件明确知道哪些Observers希望共享一个内存地址时使用,此软件通常可以知道系统的拓扑。举个例子,下图展示了一个多socket系统上,跨socket内存访问会带来极大的延迟:
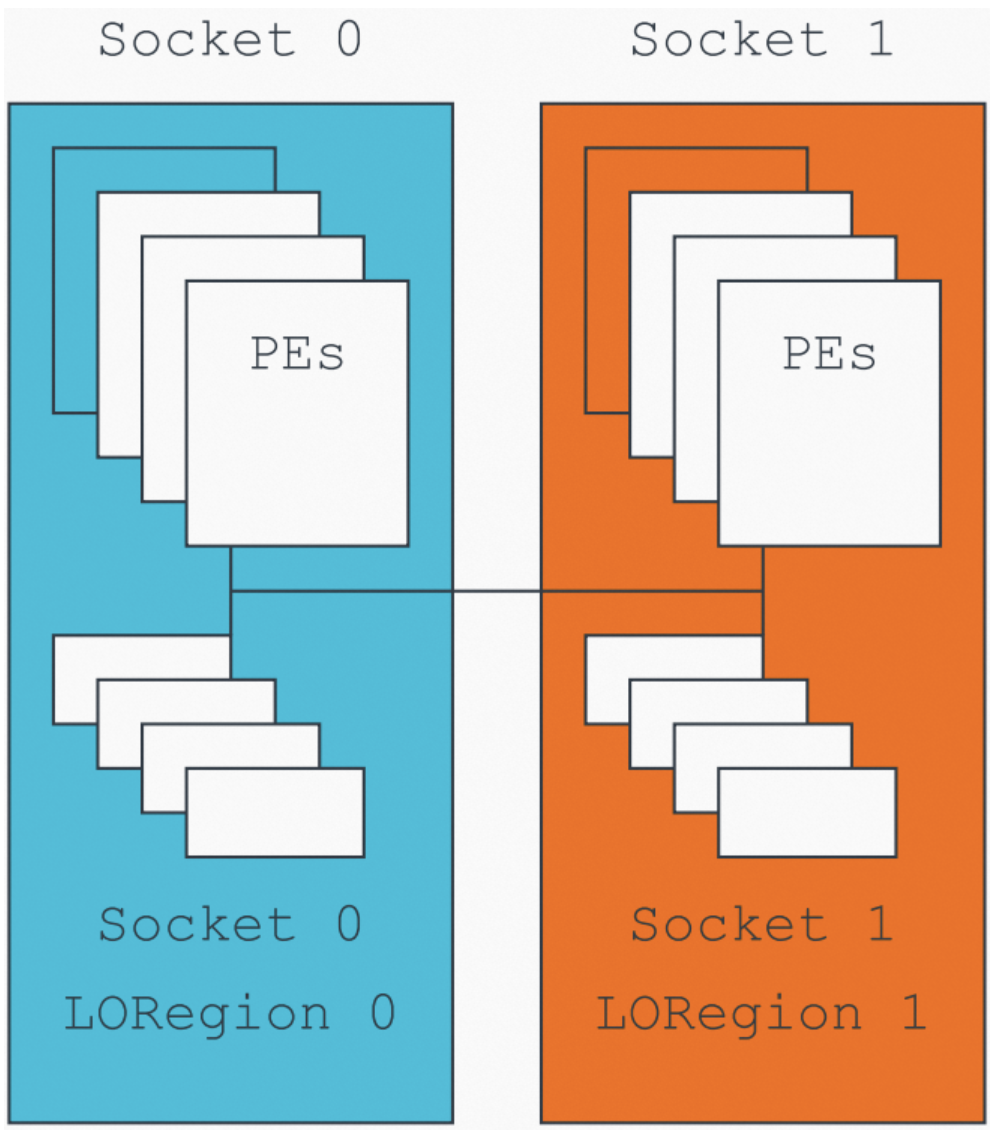
图11:使用LORegions的多socket系统
通过合理的系统设计,对一个socket所使用物理内存的本地区域应用limiting ordering(受限的保序),从而提升整体性能。
LORegions只能被应用于Non-secure物理内存访问。一个LORegion由一个LORegion descriptor描述。
LORegion descriptors的数量取决于具体的体系结构实现,可以通过读取LORID\_EL1寄存器获取。
一个LORegion descriptor包含以下信息,通过系统寄存器来编程:
- 起始地址(LORSA\_EL1)。
- 结束地址(LOREA\_EL1)。
- LORegion数量(LORN\_EL1)。
- 表征LORegion descriptor是否合法的valid bit(LORC\_EL1)。
以下代码展示对2个LORegion进行编程:
MOV x0, #0x2 // LORegion numberMOV x1, #0x80000000 // LORegion start address
MOV x2, #0xC0000000 // LORegion end address
MOV x3, #0x1 // LORegion enable (valid bit)
MSR LORN_EL1, x0 // Select the LORegion number descriptor
ISB
MSR LORSA_EL1, x1
MSR LOREA_EL1, x2
MSR LORC_EL1, x3
ISB
下图中,只有对相同LORegion中地址(由LDLAR或STLLR指令指定)的访问才会受影响,对LORegion之外的内存访问不受影响。举例来说,对C的store会先于LDLAR被观察到。如果软件使用了一个LDAR,则对C的store会在LDAR之后被观察到,如图中所示:
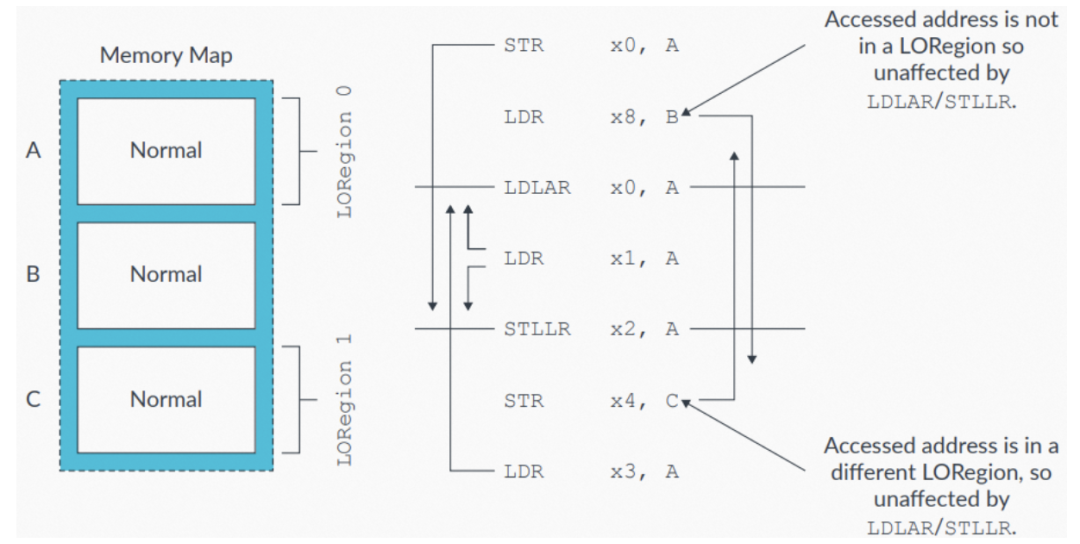
图12:LORegion内存访问示例
13 指令屏障(instruction barriers)
Arm体系结构下PE的上下文包括caches、TLBs以及系统寄存器的状态。对cache或TLB的maintenance操作或对系统寄存器的更新属于一种上下文变更(context-changing)操作。
体系结构只保证一个上下文变更操作在一个上下文同步(context synchronization)事件之后被观察到(译者:原文这里用的动词是seen,不是observed,我这里翻译成“观察”不知是否恰当,也许翻译为“生效”更佳。这里想表达的意思应该是,在做完上下文变更操作之后,必须再触发一个上下文同步事件,此变更方能生效)。
对explicit上下文同步的约束,让处理器设计者无需在每个cycle上传播所有上下文变更(译者注:意思就是把问题抛给程序员了从而解放了处理器的设计者,必须由程序进行explicit的上下文同步事件之后,上下文变更才生效,否则就必须要CPU在每个cycle上主动做一次上下文变更同步,这个就heavy多了),implicit上下文同步是非必要的开销(译者:意思就是让CPU在每个cycle上做上下文同步——这就是implicit上下文同步——会引入无谓的开销)。故软件在希望应用一个新的上下文时,需要显式发起一个上下文同步事件。
以下事情中任一为一个上下文同步事件:
- 执行一个ISB操作。
- 触发异常(译者:takes an exception,这里的take应该翻译为“触发”还是“处理”,笔者拿不准)。
- 从一个异常中返回。
- 从Debug状态中退出。
注意:Arm处理器实现,允许只要PE不发出上下文同步事件,就始终不为后续的执行更新它们的上下文。
执行一个上下文同步事件可以确保:
- 所有在上下文同步事件执行时间点上pending的umasked中断,都可以在上下文同步事件后的第一条指令之前被处理。
- program order上,任意位于一个可以触发上下文同步事件指令之后的指令,在上下文同步事件发生之前,皆不能发挥其任意部分功能(译者:其实就是想表达“压根没有一丁点被执行到的可能”)。
- 在上下文同步事件之前的所有系统寄存器writes,都会影响program order上位于触发上下文同步事件的指令之后的所有指令(译者:因为根据定义,对系统寄存器的write就是一种上下文变更,而上下文变更在上下文同步事件之后就会生效,所以会影响到后续指令。下面两条同理)。
- 所有对页表的已完成变更,如果其entries在变更之前,不允许缓存在一个TLB中,会影响所有在program order上位于触发上下文同步事件指令之后的指令预取。
- 所有在上下文同步事件之前完成的TLBs、指令 cache以及AArch32状态下的分支预测invalidation,会影响所有在program order上位于触发上下文同步事件指令之后的指令。
13.1 使用示例
假设软件必须先确保对SVE、Advanced SIMD以及浮点寄存器的访问不会trapped(译者:这里trapped我不明白是指触发异常还是会导致VMExit)。
举个例子,EL1下运行时,对SVE、Advanced SIMD以及浮点寄存器访问的trapping,可以通过将CPACR\_EL1.FPEN编程为0x3来禁能,如下面的代码所示:
MRS X1, CPACR_EL1
ORR X1, X1, #(0x3 << 20) ; Write CPACR_EL1.FPEN bits
MSR CPACR_EL1, X1
ISB
FADD S0, S1, S2
如果没有ISB指令,则对trapping的禁能(是一个上下文变更操作)并不保证能被FADD指令观察到(译者:would not be guaranteed to be seen by the FADD instruction,这里原文用的又是seen,理解为“在FADDR指令执行时此上下文变更已生效”)。不加ISB的话会导致FADD指令触发一个Synchronous异常。
本场景下,ISB作为一个上下文同步事件,其用来确保新的上下文(此“新的上下文”也就是对SVE、Advanced SIMD以及浮点寄存器trap的禁能)可以被FADD指令观察到。
本例子中,如果在对SVE、Advanced SIMD以及浮点寄存器进行访问之前,从EL1返回到了EL0,则无需ISB。这是因为从EL1到EL0的异常返回也是一个上下文同步事件。
14 知识检验
Q1:啥是Observer?
A1:Observer是一个处理单元或系统部件,比如外设,可以向内存发起读写。
Q2:如果我要确保由一个DMB分开的两个stores,被同Inner Shareable domain中的其他Observers按序观察到,应该使用啥参数?
A2:DMB ISHST。
Q3:如果要确保此前的内存访问都已完成后再继续执行,应该使用什么内存屏障?
A3:DSB。
Q4:啥是architecturally定义的上下文同步事件?
A4:architecturally定义的上下文同步事件包括以下:
- 执行一个ISB操作。
- 触发一个异常。
- 从一个异常中返回。
- 从Debug状态返回。
15 相关信息
下面是一些与本guide相关的材料:
1. Arm v8-A Architecture Reference Manual。特别是以下章节:
- Barrier Litmus Tests
- The AArch64 Application Level Memory Model
2. Arm社区:
https://community.arm.com/
3.Learn the architecture - AArch64 memory model:
https://developer.arm.com/documentation/102376/latest
4. Memory Consistency Models for Shared Memory-Multiprocessors, Gharachorloo, Kourosh, 1995, Stanford University Technical Report CSL-TR-95-685
(http://infolab.stanford.edu/pub/cstr/reports/csl/tr/95/685/CSL-TR-95-685.pdf):该论文提供了RSsc以及RCpc方面的信息。
16 更进一步
更多内存及指令屏障方面的详细例子,可以参考最新Arm v8-A Architecture Reference Manual的Barrier Litmus Tests章节,该章节提供了一些需要屏障的常见场景及代码示例。
更多Arm v8-A架构的学习,参考Learn the architecture系列guides:
https://developer.arm.com/documentation#cf[navigationhierarchiesproducts]=Architectures,Learn%20the%20architecture
